Offline Hierarchical Reinforcement Learning via Inverse Optimization
Carolin Schmidt ⋅ Daniele Gammelli ⋅ James Harrison ⋅ Marco Pavone ⋅ Filipe Rodrigues
2025 Poster
{kind=link}
Abstract
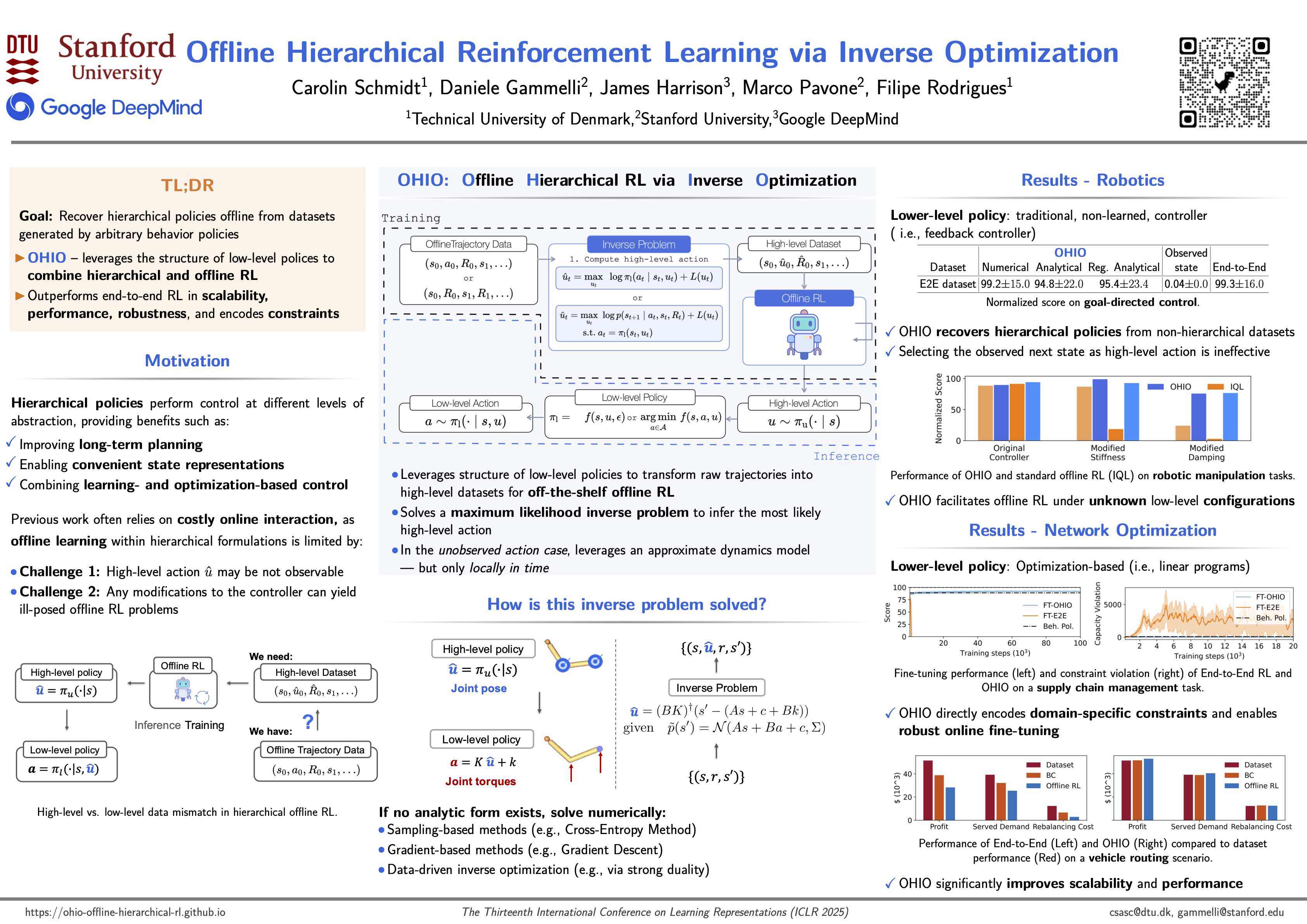
Hierarchical policies enable strong performance in many sequential decision-making problems, such as those with high-dimensional action spaces, those requiring long-horizon planning, and settings with sparse rewards. However, learning hierarchical policies from static offline datasets presents a significant challenge.Crucially, actions taken by higher-level policies may not be directly observable within hierarchical controllers, and the offline dataset might have been generated using a different policy structure, hindering the use of standard offline learning algorithms.In this work, we propose $\textit{OHIO}$: a framework for offline reinforcement learning (RL) of hierarchical policies. Our framework leverages knowledge of the policy structure to solve the $\textit{inverse problem}$, recovering the unobservable high-level actions that likely generated the observed data under our hierarchical policy.This approach constructs a dataset suitable for off-the-shelf offline training.We demonstrate our framework on robotic and network optimization problems and show that it substantially outperforms end-to-end RL methods and improves robustness. We investigate a variety of instantiations of our framework, both in direct deployment of policies trained offline and when online fine-tuning is performed. Code and data are available at https://ohio-offline-hierarchical-rl.github.io.
Video
Chat is not available.
Successful Page Load