Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
{kind=link}
Abstract
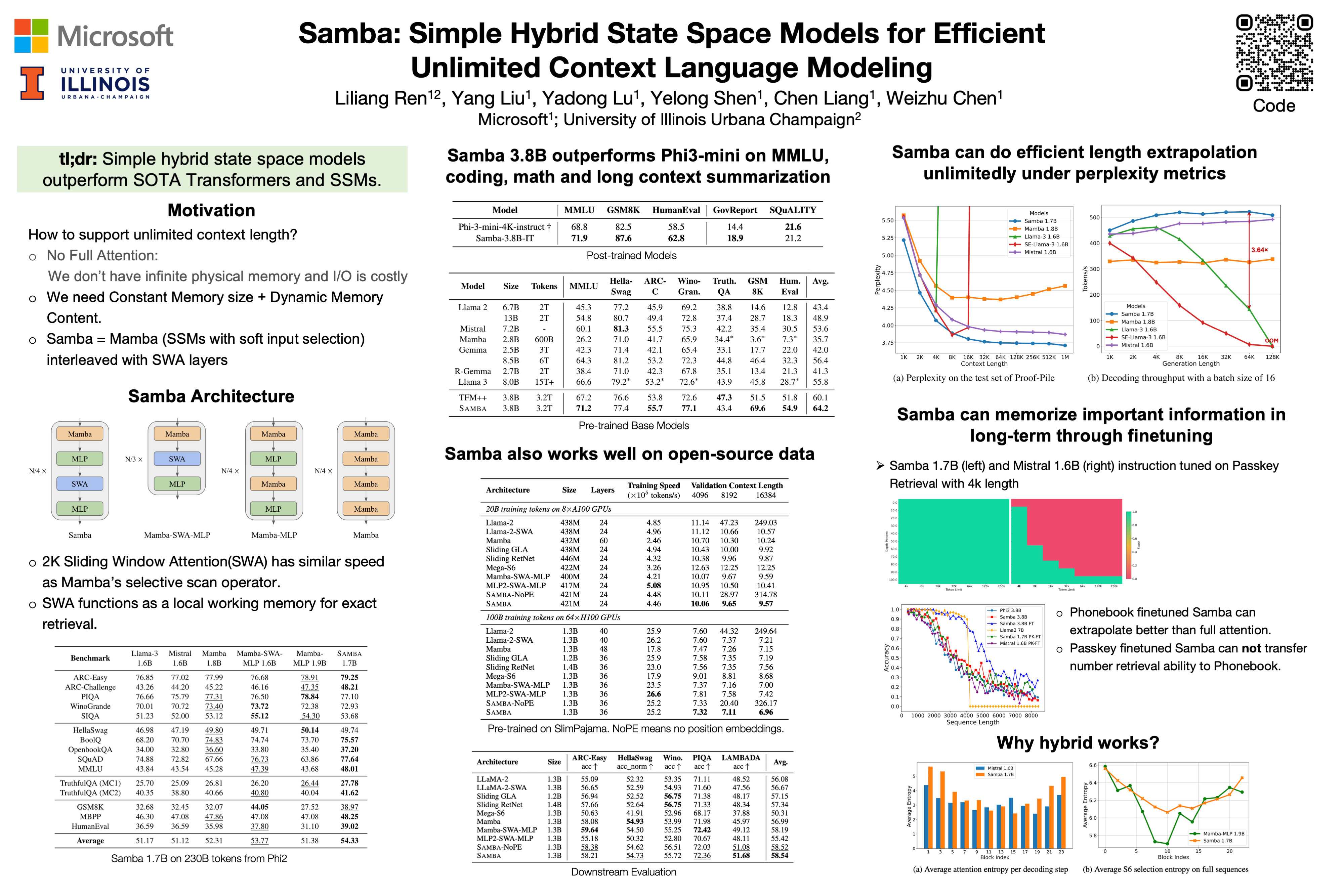
Efficiently modeling sequences with infinite context length has long been a challenging problem. Previous approaches have either suffered from quadratic computational complexity or limited extrapolation ability in length generalization. In thiswork, we present Samba, a simple hybrid architecture that layer-wise combinesMamba, a selective State Space Model (SSM), with Sliding Window Attention(SWA). Samba selectively compresses a given sequence into recurrent hiddenstates while still maintaining the ability to precisely recall recent memories with theattention mechanism. We scale Samba up to 3.8B parameters with 3.2T trainingtokens and demonstrate that it significantly outperforms state-of-the-art modelsacross a variety of benchmarks. Pretrained on sequences of 4K length, Sambashows improved perplexity in context lengths of up to 1M in zero-shot. Whenfinetuned on 4K-length sequences, Samba efficiently extrapolates to a 256K context length with perfect memory recall on the Passkey Retrieval task, and exhibitssuperior retrieval extrapolation on the challenging Phonebook task compared tofull-attention models. As a linear-time sequence model, Samba achieves a 3.73×higher throughput compared to Transformers with grouped-query attention for userprompts of 128K length, and a 3.64× speedup when generating 64K tokens withunlimited streaming.