Fine-tuning with Reserved Majority for Noise Reduction
{kind=link}
Abstract
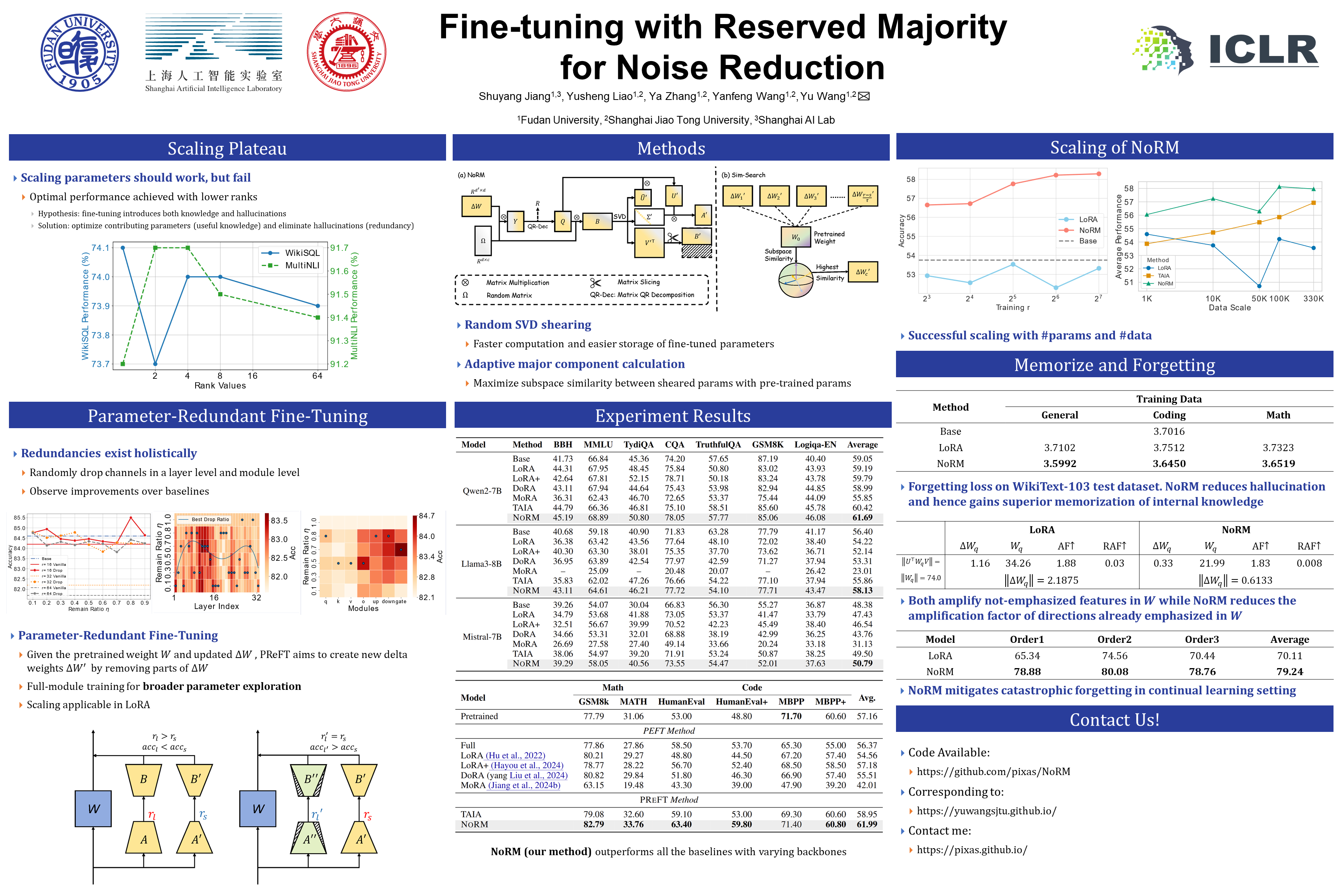
Parameter-efficient fine-tuning (PEFT) has revolutionized supervised fine-tuning, where LoRA and its variants gain the most popularity due to their low training costs and zero inference latency.However, LoRA tuning not only injects knowledgeable features but also noisy hallucination during fine-tuning, which hinders the utilization of tunable parameters with the increasing LoRA rank.In this work, we first investigate in-depth the redundancies among LoRA parameters with substantial empirical studies.Aiming to resemble the learning capacity of high ranks from the findings, we set up a new fine-tuning framework, \textbf{P}arameter-\textbf{Re}dundant \textbf{F}ine-\textbf{T}uning (\preft), which follows the vanilla LoRA tuning process but is required to reduce redundancies before merging LoRA parameters back to pre-trained models.Based on this framework, we propose \textbf{No}ise reduction with \textbf{R}eserved \textbf{M}ajority~(\norm), which decomposes the LoRA parameters into majority parts and redundant parts with random singular value decomposition.The major components are determined by the proposed \search method, specifically employing subspace similarity to confirm the parameter groups that share the highest similarity with the base weight.By employing \norm, we enhance both the learning capacity and benefits from larger ranks, which consistently outperforms both LoRA and other \preft-based methods on various downstream tasks, such as general instruction tuning, math reasoning and code generation. Code is available at \url{https://github.com/pixas/NoRM}.