Self-Improving Robust Preference Optimization
Eugene Choi ⋅ Arash Ahmadian ⋅ Matthieu Geist ⋅ Olivier Pietquin ⋅ Mohammad Gheshlaghi Azar
2025 Poster
{kind=link}
Abstract
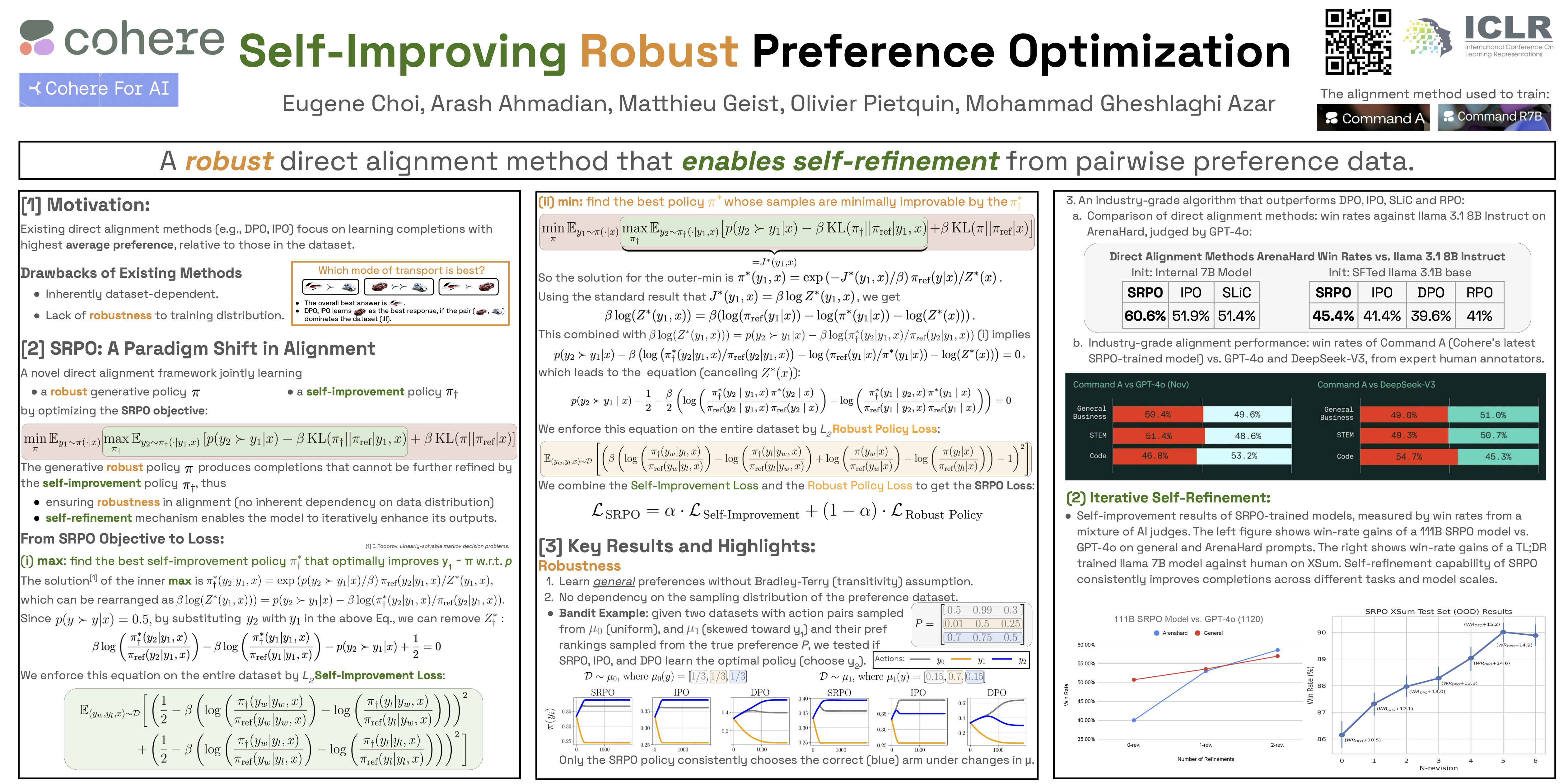
Online and offline $\mathtt{RLHF}$ methods, such as $\mathtt{PPO}$ and $\mathtt{DPO}$, have been highly successful in aligning AI with human preferences. Despite their success, however, these methods suffer from fundamental limitations: $\mathbf{(a)}$ Models trained with $\mathtt{RLHF}$ can learn from mistakes or negative examples through RL mechanism or contrastive loss during training. However, at inference time, they lack an innate self-improvement mechanism for error corrections. $\mathbf{(b)}$ The optimal solution of existing methods is highly task-dependent, making it difficult for them to generalize to new tasks. To address these challenges, we propose Self-Improving Robust Preference Optimization ($\mathtt{SRPO}$), a practical and mathematically principled offline $\mathtt{RLHF}$ framework. The key idea behind $\mathtt{SRPO}$ is to cast the problem of learning from human preferences as a self-improvement process, mathematically formulated as a min-max objective that jointly optimizes a self-improvement policy and a generative policy in an adversarial fashion. Crucially, the solution for this optimization problem is independent of the training task, which makes it robust to its changes. We then show that this objective can be reformulated as a non-adversarial offline loss, which can be efficiently optimized using standard supervised learning techniques at scale. To demonstrate $\mathtt{SRPO}$’s effectiveness, we evaluate it using AI Win-Rate (WR) against human (GOLD) completions. When tested on the XSum dataset, $\mathtt{SRPO}$ outperforms $\mathtt{DPO}$ by a margin of $\mathbf{15}$% after $5$ self-revisions, achieving an impressive $\mathbf{90}$% WR. Moreover, on the challenging Arena-Hard prompts, $\mathtt{SRPO}$ outperforms both $\mathtt{DPO}$ and $\mathtt{IPO}$ (by $\mathbf{4}$% without revision and $\mathbf{6}$% after a single revision), reaching a $\mathbf{56}$% WR against against $\mathtt{Llama-3.1-8B-Instruct}$.
Video
Chat is not available.
Successful Page Load