Attention with Markov: A Curious Case of Single-layer Transformers
{kind=link}
Abstract
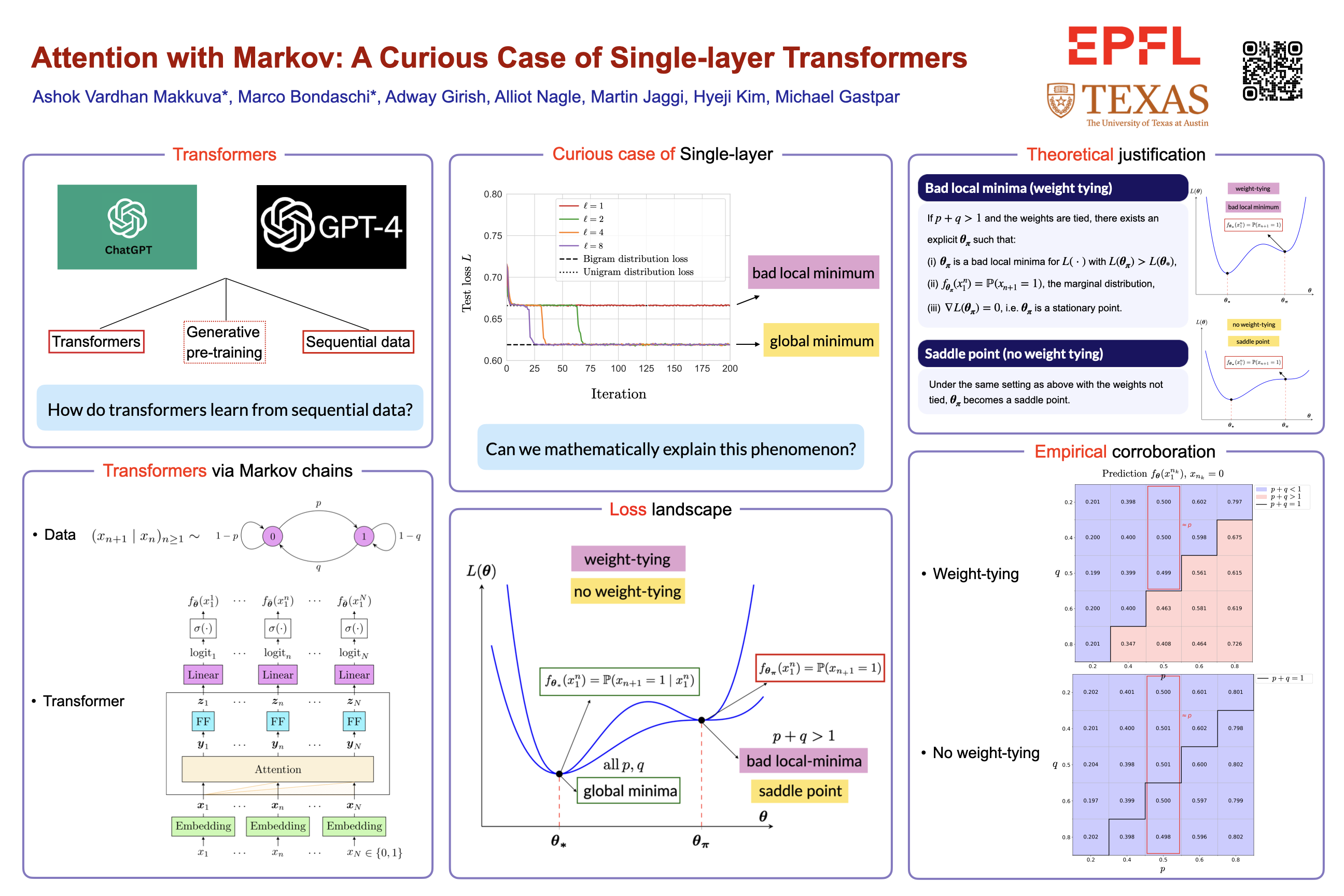
Attention-based transformers have achieved tremendous success across a variety of disciplines including natural languages. To deepen our understanding of their sequential modeling capabilities, there is a growing interest in using Markov input processes to study them. A key finding is that when trained on first-order Markov chains, transformers with two or more layers consistently develop an induction head mechanism to estimate the in-context bigram conditional distribution. In contrast, single-layer transformers, unable to form an induction head, directly learn the Markov kernel but often face a surprising challenge: they become trapped in local minima representing the unigram distribution, whereas deeper models reliably converge to the ground-truth bigram. While single-layer transformers can theoretically model first-order Markov chains, their empirical failure to learn this simple kernel in practice remains a curious phenomenon. To explain this contrasting behavior of single-layer models, in this paper we introduce a new framework for a principled analysis of transformers via Markov chains. Leveraging our framework, we theoretically characterize the loss landscape of single-layer transformers and show the existence of global minima (bigram) and bad local minima (unigram) contingent on data properties and model architecture. We precisely delineate the regimes under which these local optima occur. Backed by experiments, we demonstrate that our theoretical findings are in congruence with the empirical results. Finally, we outline several open problems in this arena.