Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training
{kind=link}
Abstract
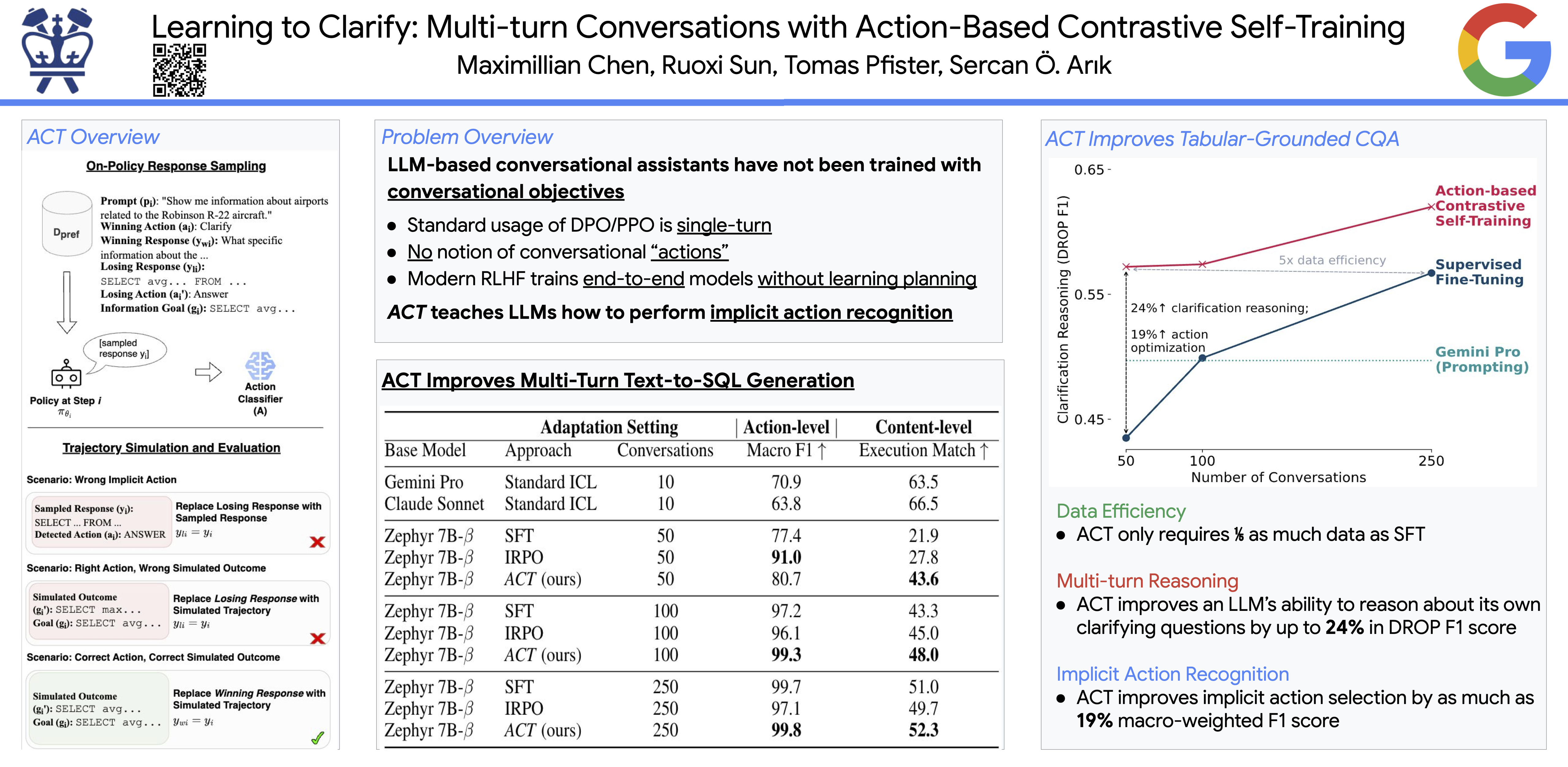
Large language models (LLMs), optimized through human feedback, have rapidly emerged as a leading paradigm for developing intelligent conversational assistants. However, despite their strong performance across many benchmarks, LLM-based agents might still lack conversational skills such as disambiguation -- when they are faced with ambiguity, they often overhedge or implicitly guess users' true intents rather than asking clarification questions. Under task-specific settings, high-quality conversation samples are often limited, constituting a bottleneck for LLMs' ability to learn optimal dialogue action policies. We propose Action-Based Contrastive Self-Training (ACT), a quasi-online preference optimization algorithm based on Direct Preference Optimization (DPO), that enables data-efficient dialogue policy learning in multi-turn conversation modeling. We demonstrate ACT's efficacy under data-efficient tuning scenarios, even when there is no action label available, using multiple real-world conversational tasks: tabular-grounded question-answering, machine reading comprehension, and AmbigSQL, a novel task for disambiguating information-seeking requests for complex SQL generation towards data analysis agents. Additionally, we propose evaluating LLMs' ability to function as conversational agents by examining whether they can implicitly recognize and reason about ambiguity in conversation. ACT demonstrates substantial conversation modeling improvements over standard tuning approaches like supervised fine-tuning and DPO.