LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Models for Referring Expression Comprehension
{kind=link}
Abstract
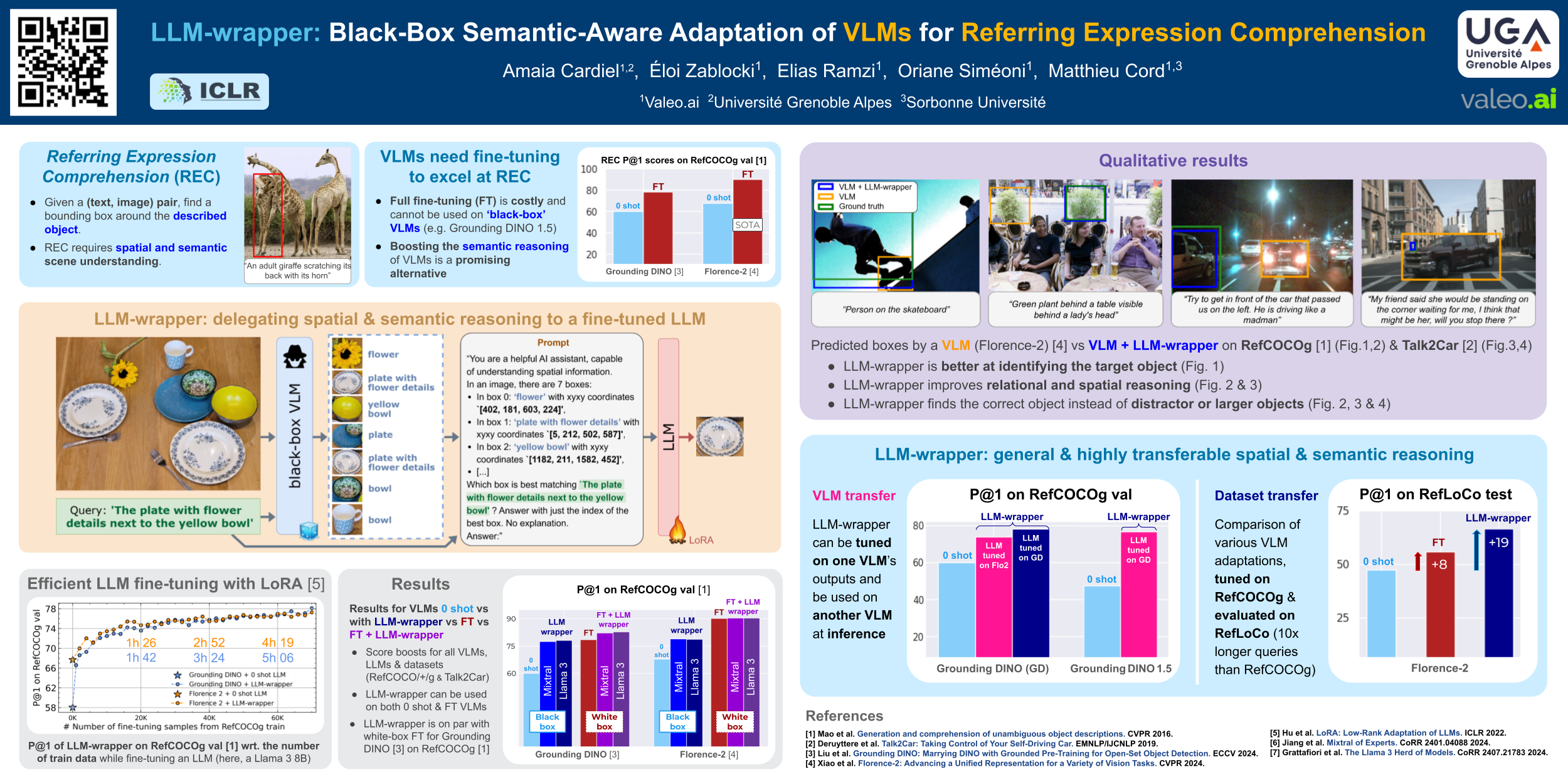
Vision Language Models (VLMs) have demonstrated remarkable capabilities in various open-vocabulary tasks, yet their zero-shot performance lags behind task-specific fine-tuned models, particularly in complex tasks like Referring Expression Comprehension (REC). Fine-tuning usually requires ‘white-box’ access to the model’s architecture and weights, which is not always feasible due to proprietary or privacy concerns. In this work, we propose LLM-wrapper, a method for ‘black-box’ adaptation of VLMs for the REC task using Large Language Models (LLMs). LLM-wrapper capitalizes on the reasoning abilities of LLMs, improved with a light fine-tuning, to select the most relevant bounding box to match the referring expression, from candidates generated by a zero-shot black-box VLM. Our approach offers several advantages: it enables the adaptation of closed-source models without needing access to their internal workings, it is versatile and works with any VLM, transfers to new VLMs, and it allows for the adaptation of an ensemble of VLMs. We evaluate LLM-wrapper on multiple datasets using different VLMs and LLMs, demonstrating significant performance improvements and highlighting the versatility of our method. While LLM-wrapper is not meant to directly compete with standard white-box fine-tuning, it offers a practical and effective alternative for black-box VLM adaptation. The code will be open-sourced.