Weighted Multi-Prompt Learning with Description-free Large Language Model Distillation
{kind=link}
Abstract
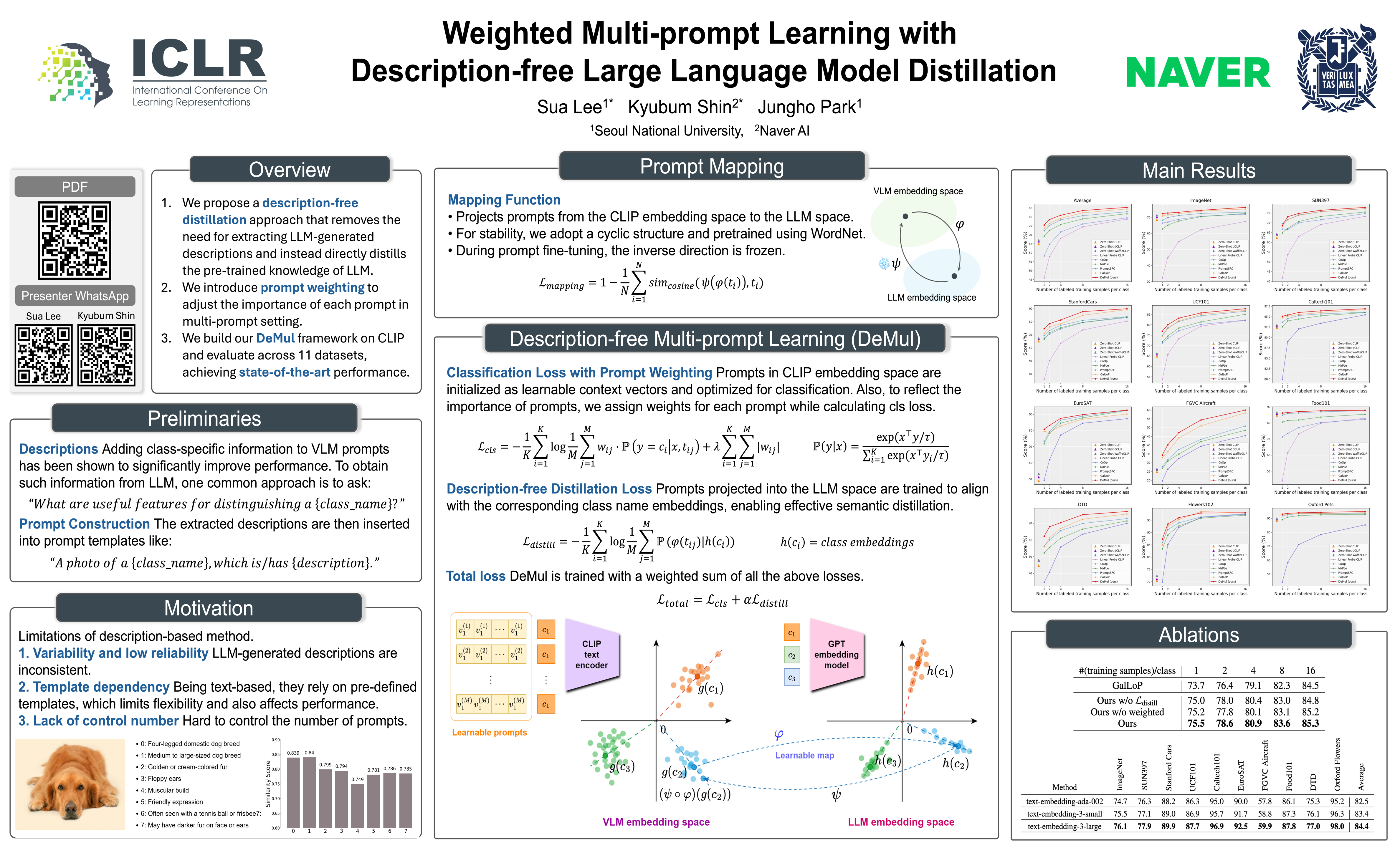
Recent advances in pre-trained Vision Language Models (VLM) have shown promising potential for effectively adapting to downstream tasks through prompt learning, without the need for additional annotated paired datasets.To supplement the text information in VLM trained on correlations with vision data, new approaches leveraging Large Language Models (LLM) in prompts have been proposed, enhancing robustness to unseen and diverse data.Existing methods typically extract text-based responses (i.e., descriptions) from LLM to incorporate into prompts; however, this approach suffers from high variability and low reliability.In this work, we propose Description-free Multi-prompt Learning(DeMul), a novel method that eliminates the process of extracting descriptions and instead directly distills knowledge from LLM into prompts.By adopting a description-free approach, prompts can encapsulate richer semantics while still being represented as continuous vectors for optimization, thereby eliminating the need for discrete pre-defined templates.Additionally, in a multi-prompt setting, we empirically demonstrate the potential of prompt weighting in reflecting the importance of different prompts during training.Experimental results show that our approach achieves superior performance across 11 recognition datasets.