MAVIS: Mathematical Visual Instruction Tuning with an Automatic Data Engine
{kind=link}
Abstract
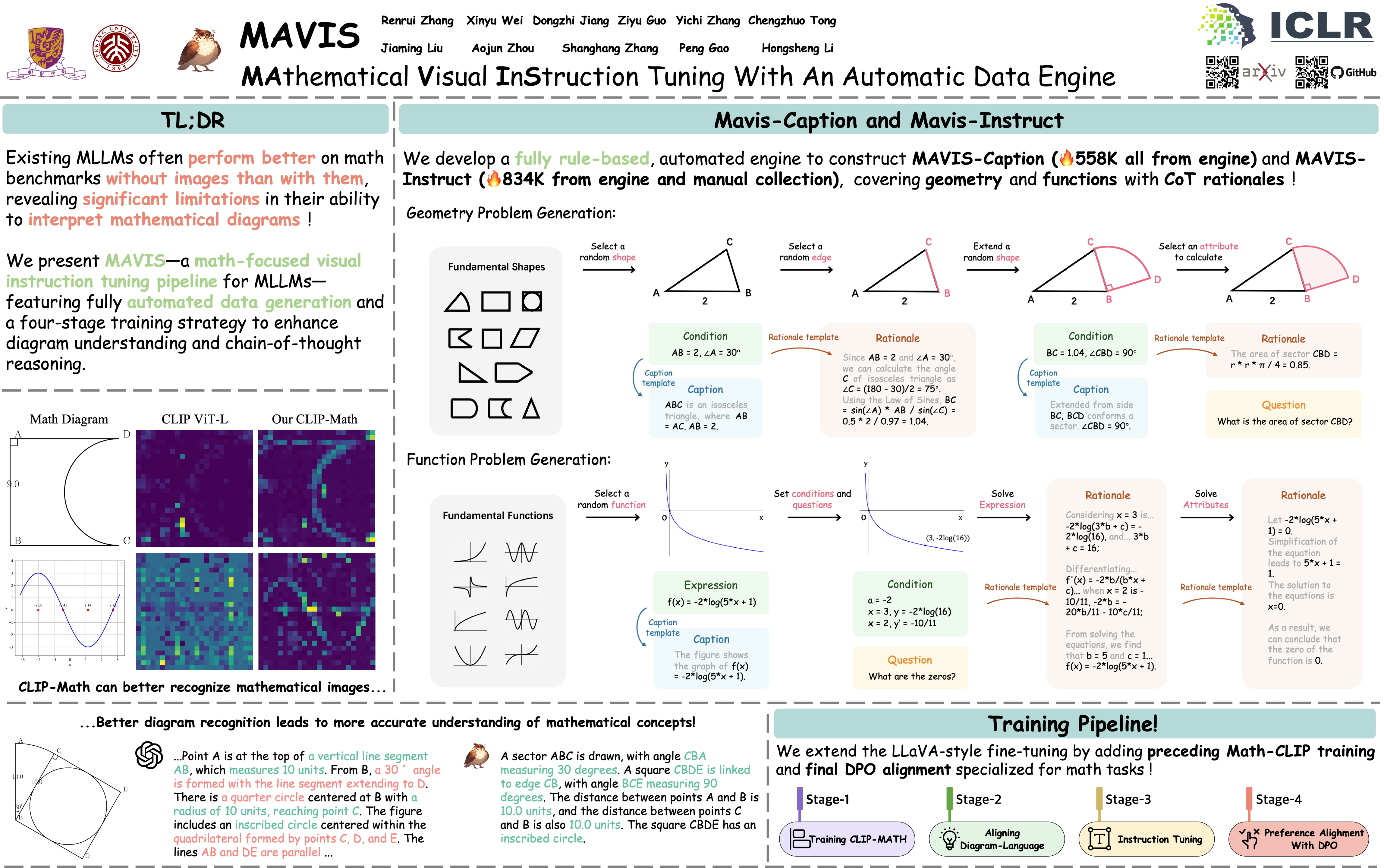
Multi-modal Large Language Models (MLLMs) have recently showcased superior proficiency in general visual scenarios. However, we identify their mathematical capabilities remain under-explored with three areas to be improved: visual encoding of math diagrams, diagram-language alignment, and chain-of-thought (CoT) reasoning. This draws forth an urgent demand for an effective training paradigm and a large-scale, comprehensive dataset with detailed CoT rationales, which is challenging to collect and costly to annotate manually. To tackle this issue, we propose MAVIS, a MAthematical VISual instruction tuning pipeline for MLLMs, featuring an automatic data engine to efficiently create mathematical visual datasets.We design the data generation process to be entirely independent of human intervention or GPT API usage, while ensuring the diagram-caption correspondence, question-answer correctness, and CoT reasoning quality. With this approach, we curate two datasets, MAVIS-Caption (558K diagram-caption pairs) and MAVIS-Instruct (834K visual math problems with CoT rationales), and propose four progressive stages for training MLLMs from scratch.First, we utilize MAVIS-Caption to fine-tune a math-specific vision encoder (CLIP-Math) through contrastive learning, tailored for improved diagram visual encoding. Second, we also leverage MAVIS-Caption to align the CLIP-Math with a large language model (LLM) by a projection layer, enhancing vision-language alignment in mathematical domains. Third, we adopt MAVIS-Instruct to perform the instruction tuning for robust problem-solving skills, and term the resulting model as MAVIS-7B. Fourth, we apply Direct Preference Optimization (DPO) to enhance the CoT capabilities of our model, further refining its step-wise reasoning performance.On various mathematical benchmarks, our MAVIS-7B achieves leading results among open-source MLLMs, e.g., surpassing other 7B models by +9.3% and the second-best LLaVA-NeXT (110B) by +6.9%, demonstrating the effectiveness of our method.