Frame-Voyager: Learning to Query Frames for Video Large Language Models
{kind=link}
Abstract
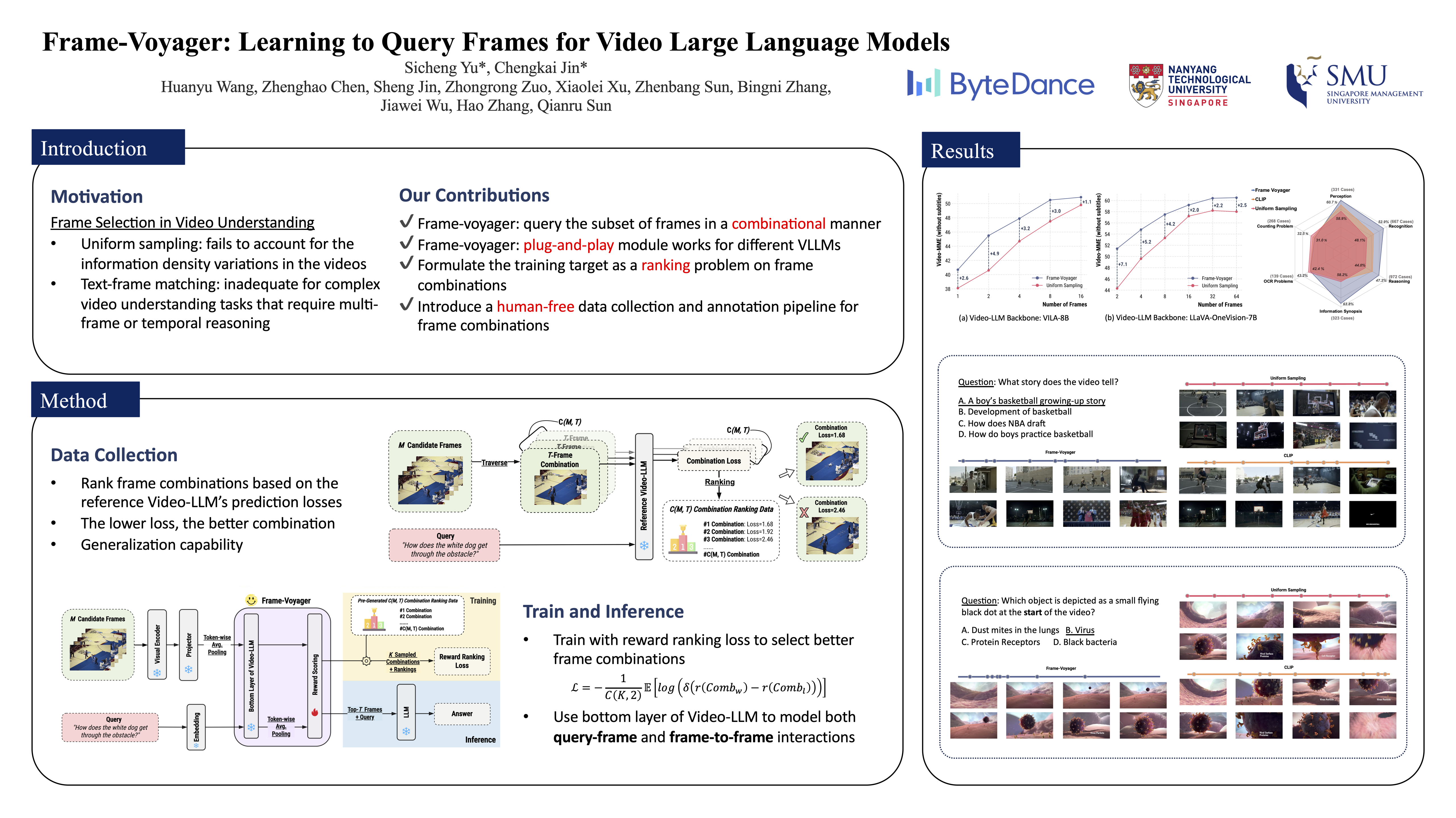
Video Large Language Models (Video-LLMs) have made remarkable progress in video understanding tasks. However, they are constrained by the maximum length of input tokens, making it impractical to input entire videos. Existing frame selection approaches, such as uniform frame sampling and text-frame retrieval, fail to account for the information density variations in the videos or the complex instructions in the tasks, leading to sub-optimal performance. In this paper, we propose Frame-Voyager that learns to query informative frame combinations, based on the given textual queries in the task. To train Frame-Voyager, we introduce a new data collection and labeling pipeline, by ranking frame combinations using a pre-trained Video-LLM. Given a video of M frames, we traverse its T-frame combinations, feed them into a Video-LLM, and rank them based on Video-LLM's prediction losses. Using this ranking as supervision, we train Frame-Voyager to query the frame combinations with lower losses. In experiments, we evaluate Frame-Voyager on four Video Question Answering benchmarks by plugging it into two different Video-LLMs. The experimental results demonstrate that Frame-Voyager achieves impressive results in all settings, highlighting its potential as a plug-and-play solution for Video-LLMs.