SoundCTM: Unifying Score-based and Consistency Models for Full-band Text-to-Sound Generation
Koichi Saito ⋅ Dongjun Kim ⋅ Takashi Shibuya ⋅ Chieh-Hsin Lai ⋅ Zhi Zhong ⋅ Yuhta Takida ⋅ Yuki Mitsufuji
2025 Poster
{kind=link}
Abstract
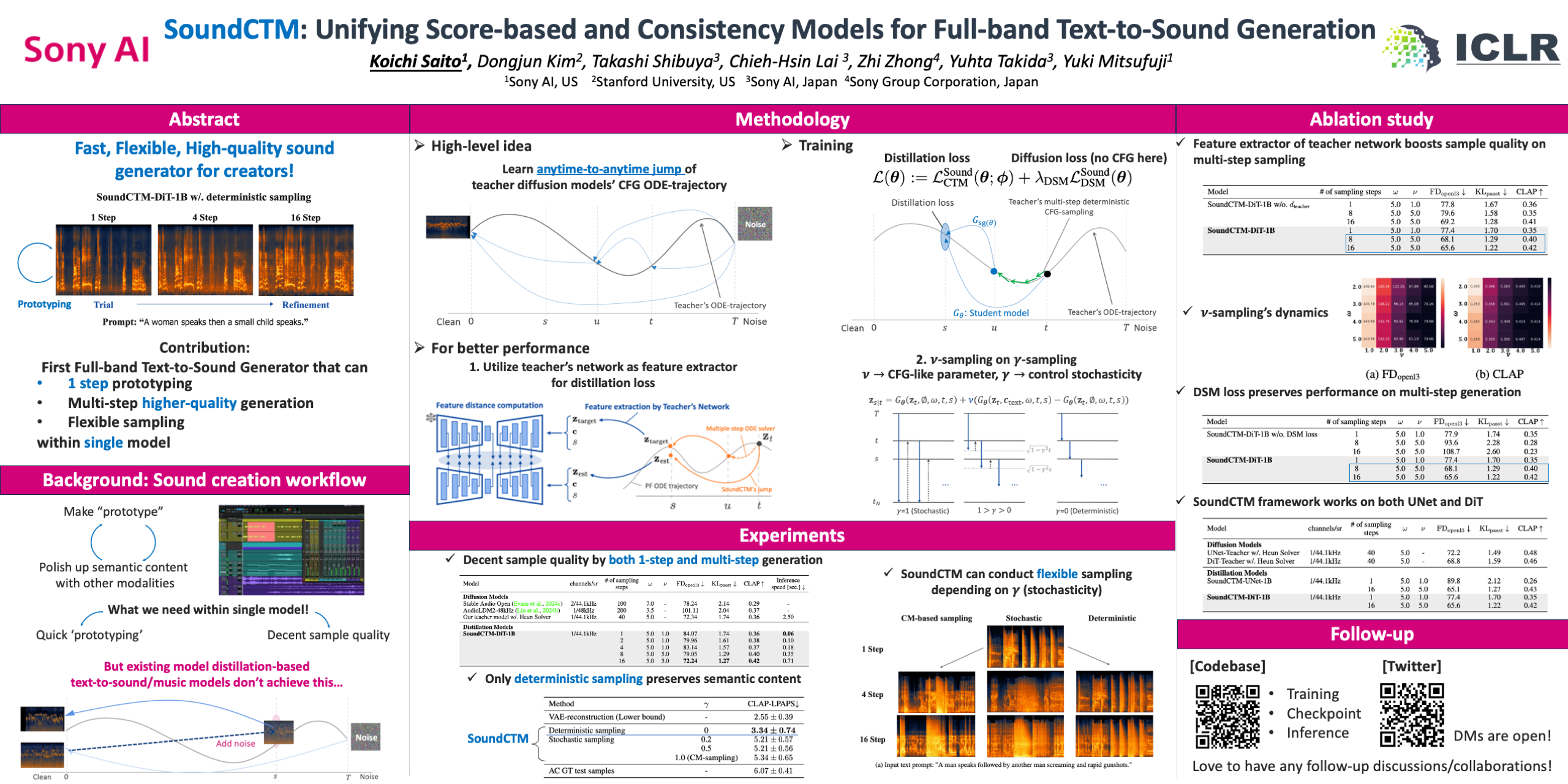
Sound content creation, essential for multimedia works such as video games and films, often involves extensive trial-and-error, enabling creators to semantically reflect their artistic ideas and inspirations, which evolve throughout the creation process, into the sound.Recent high-quality diffusion-based Text-to-Sound (T2S) generative models provide valuable tools for creators. However, these models often suffer from slow inference speeds, imposing an undesirable burden that hinders the trial-and-error process.While existing T2S distillation models address this limitation through $1$-step generation, the sample quality of $1$-step generation remains insufficient for production use.Additionally, while multi-step sampling in those distillation models improves sample quality itself, the semantic content changes due to their lack of deterministic sampling capabilities.Thus, developing a T2S generative model that allows creators to efficiently conduct trial-and-error while producing high-quality sound remains a key challenge.To address these issues, we introduce Sound Consistency Trajectory Models (SoundCTM), which allow flexible transitions between high-quality $1$-step sound generation and superior sound quality through multi-step deterministic sampling. This allows creators to efficiently conduct trial-and-error with $1$-step generation to semantically align samples with their intention, and subsequently refine sample quality with preserving semantic content through deterministic multi-step sampling.To develop SoundCTM, we reframe the CTM training framework, originally proposed in computer vision, and introduce a novel feature distance using the teacher network for a distillation loss. Additionally, while distilling classifier-free guided trajectories, we introduce a $\nu$-sampling, a new algorithm that offers another source of quality improvement. For the $\nu$-sampling, we simultaneously train both conditional and unconditional student models.For production-level generation, we scale up our model to 1B trainable parameters, making SoundCTM-DiT-1B the first large-scale distillation model in the sound community to achieve both promising high-quality $1$-step and multi-step full-band (44.1kHz) generation.Audio samples are available at \url{https://anonymus-soundctm.github.io/soundctm_iclr/}.
Video
Chat is not available.
Successful Page Load