Distilling Structural Representations into Protein Sequence Models
{kind=link}
Abstract
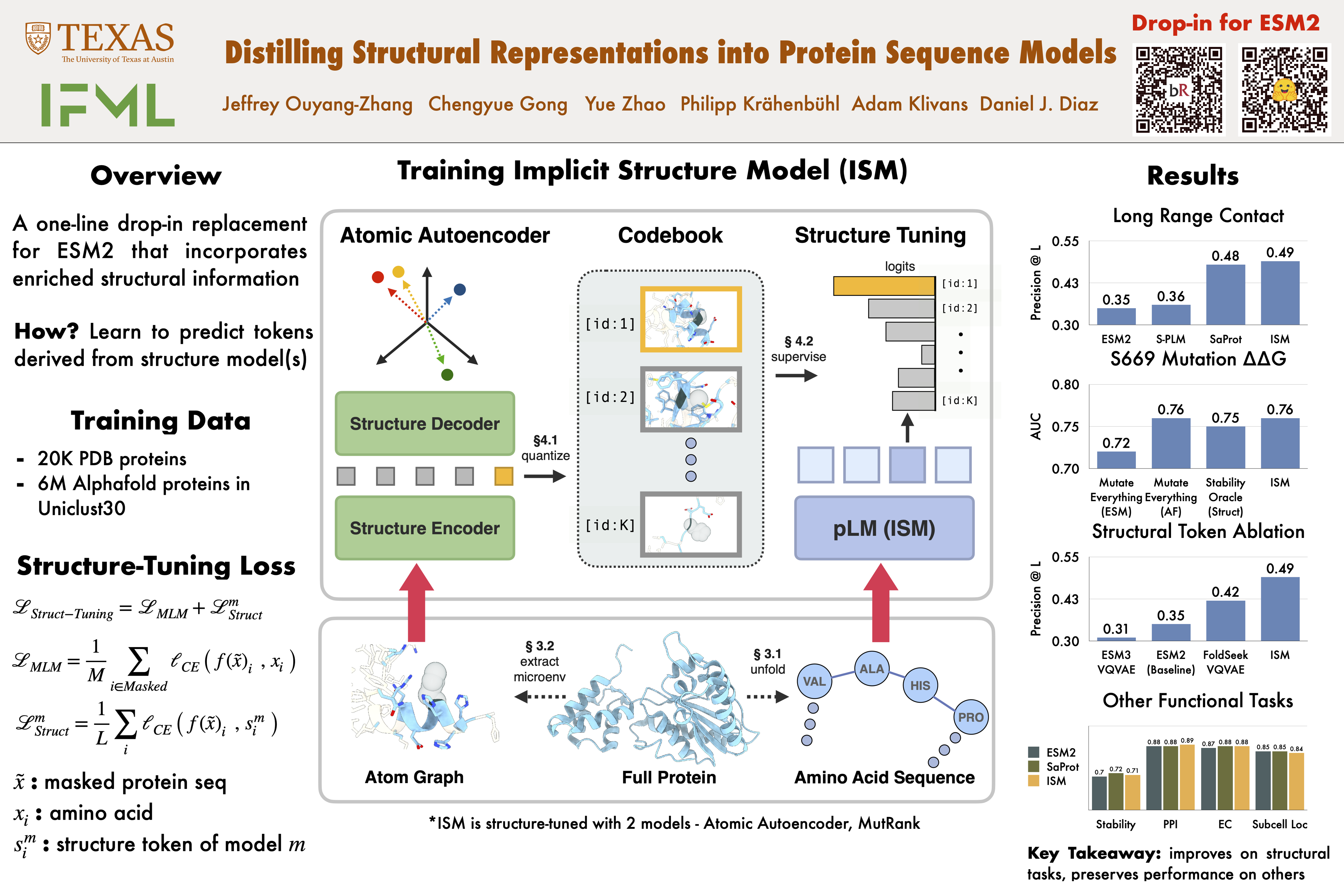
Protein language (or sequence) models, like the popular ESM2, are now widely used tools for extracting evolution-based protein representations and have achieved significant success on core downstream biological tasks.A major open problem is how to obtain representations that best capture both the sequence evolutionary history and the atomic structural properties of proteins in general. We introduce Implicit Sequence Model, a sequence-only input model with structurally-enriched representations that outperforms state-of-the-art sequence models on several well-studied benchmarks including mutation stability assessment and structure prediction. Our key innovations are a microenvironment-based Autoencoder for generating structure tokens and a self-supervised training objective that distills these tokens into ESM2's pre-trained model. Notably, we make ISM's structure-enriched weights easily accessible for any application using the ESM2 framework.