Accelerated training through iterative gradient propagation along the residual path
{kind=link}
Abstract
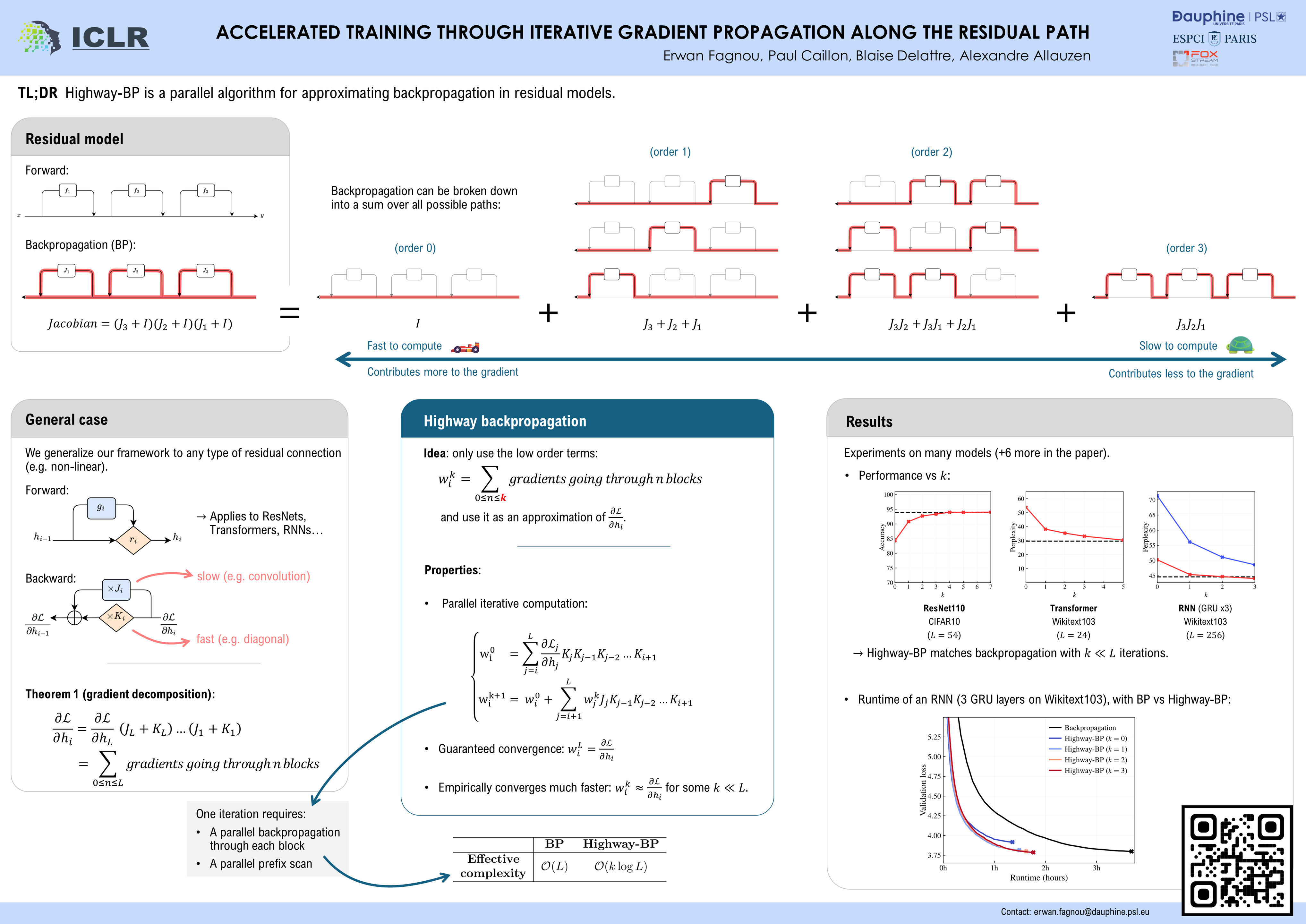
Despite being the cornerstone of deep learning, backpropagation is criticized for its inherent sequentiality, which can limit the scalability of very deep models.Such models faced convergence issues due to vanishing gradient, later resolved using residual connections. Variants of these are now widely used in modern architectures.However, the computational cost of backpropagation remains a major burden, accounting for most of the training time.Taking advantage of residual-like architectural designs, we introduce Highway backpropagation, a parallelizable iterative algorithm that approximates backpropagation, by alternatively i) accumulating the gradient estimates along the residual path, and ii) backpropagating them through every layer in parallel. This algorithm is naturally derived from a decomposition of the gradient as the sum of gradients flowing through all paths, and is adaptable to a diverse set of common architectures, ranging from ResNets and Transformers to recurrent neural networks.Through an extensive empirical study on a large selection of tasks and models, we evaluate Highway-BP and show that major speedups can be achieved with minimal performance degradation.