On Stochastic Contextual Bandits with Knapsacks in Small Budget Regime
Hengquan Guo ⋅ Xin Liu
2025 Poster
{kind=link}
Abstract
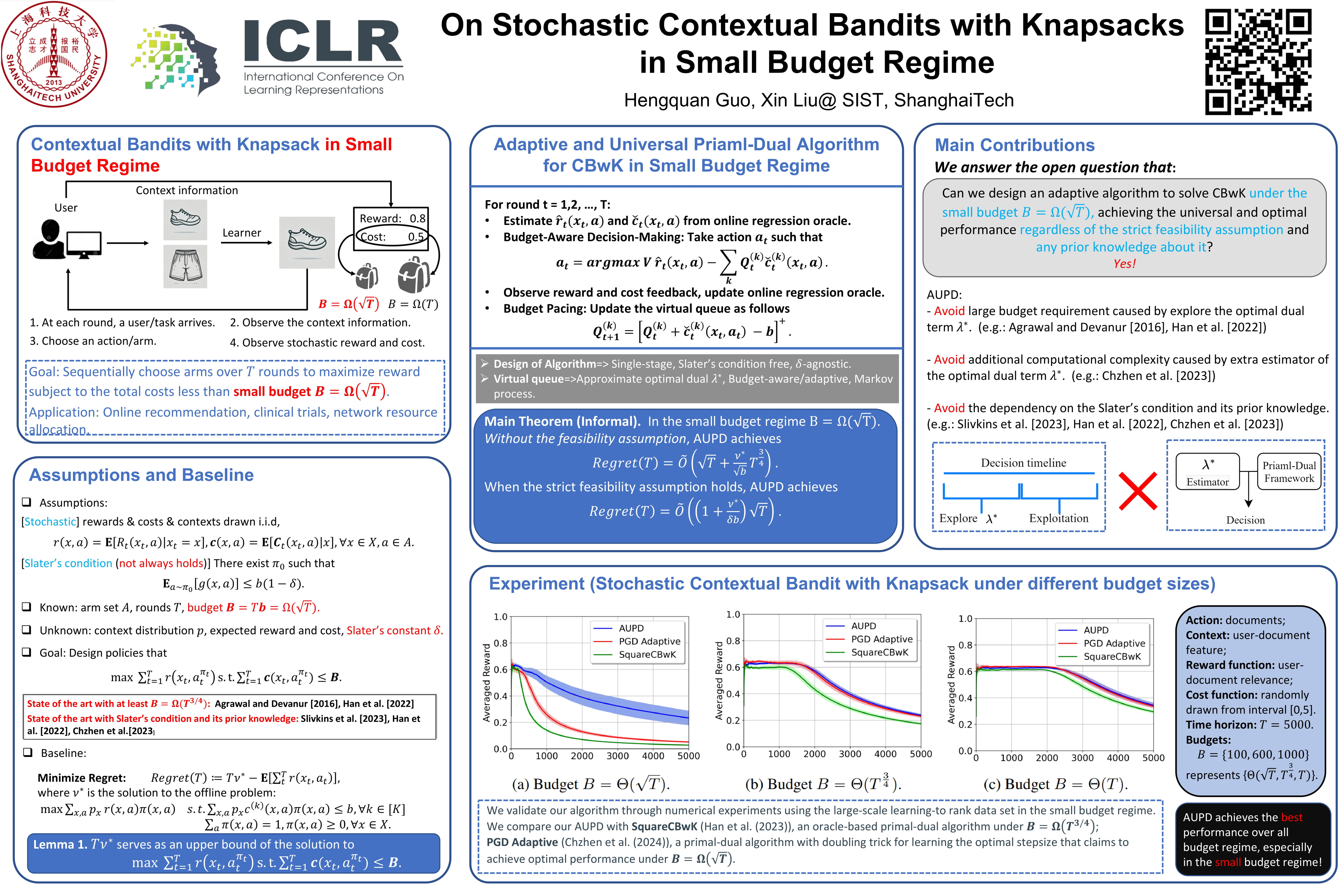
This paper studies stochastic contextual bandits with knapsack constraints (CBwK), where a learner observes a context, takes an action, receives a reward, and incurs a vector of costs at every round. The learner aims to maximize the cumulative rewards across $T$ rounds under the knapsack constraints with an initial budget of $B$. We study CBwK in the small budget regime where the budget $B = \Omega(\sqrt{T})$and propose an Adaptive and Universal Primal--Dual algorithm (AUPD) that achieves strong regret performance: i) AUPD achieves $\tilde{O}((1 + \frac{\nu^*}{\delta b})\sqrt{T})$ regret under the strict feasibility assumption without any prior information, matching the best-known bounds;ii) AUPD achieves $\tilde{O}(\sqrt{T}+ \frac{\nu^*}{\sqrt{b}}T^{\frac{3}{4}})$ regret without strict feasibility assumption, which, to the best of our knowledge, is the first result in the literature. Here, the parameter $\nu^*$ represents the optimal average reward; $b=B/T$ is the average budget and $\delta b$ is the feasibility/safety margin.We establish these strong results through the adaptive budget-aware design, which effectively balances reward maximization and budget consumption. We provide a new perspective on analyzing budget consumption using the Lyapunov drift method, along with a refined analysis of its cumulative variance. Our theory is further supported by experiments conducted on a large-scale dataset.
Video
Chat is not available.
Successful Page Load