On Linear Representations and Pretraining Data Frequency in Language Models
{kind=link}
Abstract
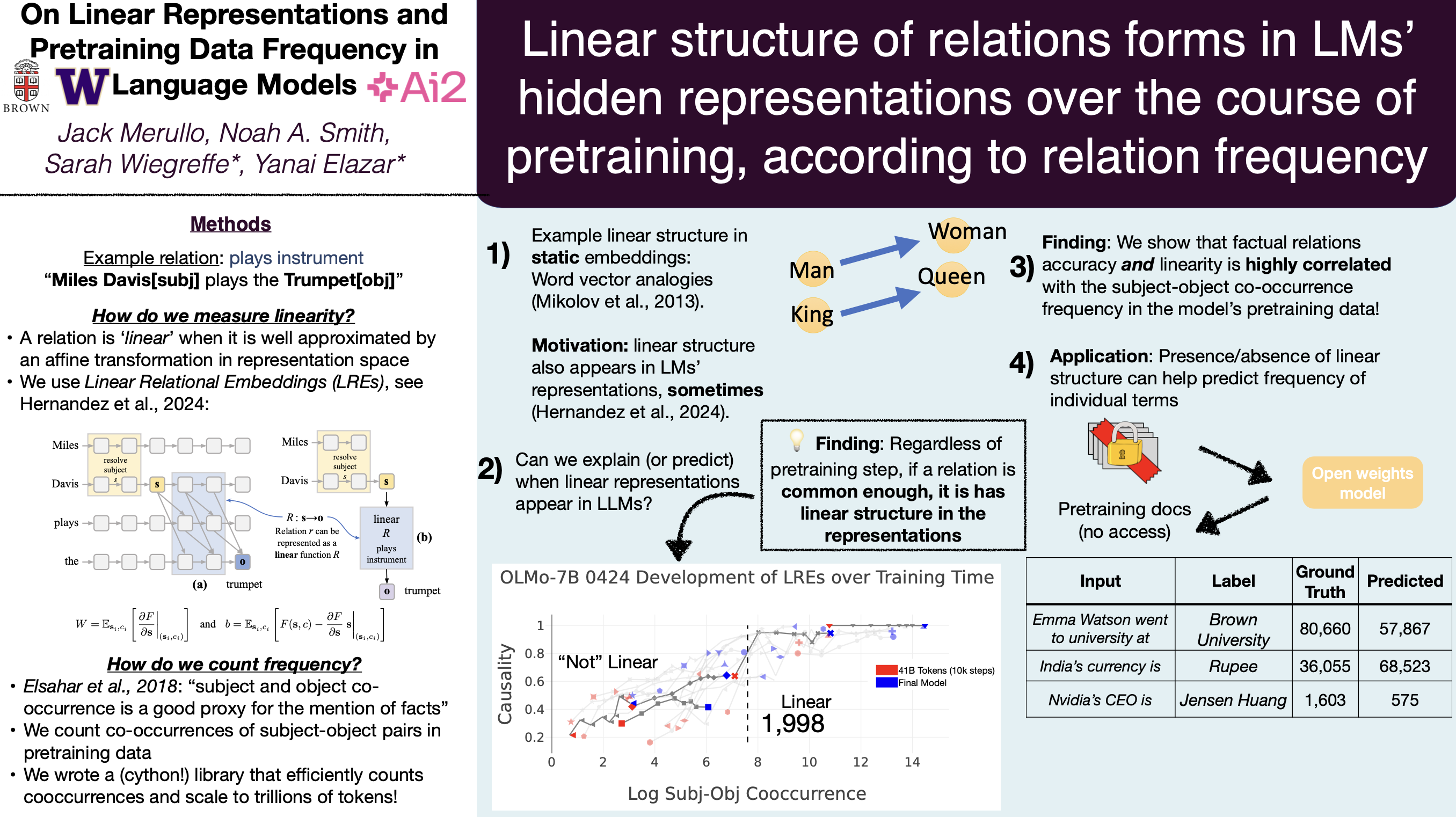
Pretraining data has a direct impact on the behaviors and quality of language models (LMs), but we only understand the most basic principles of this relationship. While most work focuses on pretraining data's effect on downstream task behavior, we investigate its relationship to LM representations. Previous work has discovered that, in language models, some concepts are encoded "linearly" in the representations, but what factors cause these representations to form (or not)? We study the connection between pretraining data frequency and models' linear representations of factual relations (e.g., mapping France to Paris in a capital prediction task). We find evidence that the formation of linear representations is strongly connected to pretraining term frequencies; specifically for subject-relation-object fact triplets, both subject-object co-occurrence frequency and in-context learning accuracy for the relation are highly correlated with linear representations. This is the case across all phases of pretraining, i.e., it is not affected by the model's underlying capability. In OLMo-7B and GPT-J (6B), we discover that a linear representation consistently (but not exclusively) forms when the subjects and objects within a relation co-occur at least 1k and 2k times, respectively, regardless of when these occurrences happen during pretraining (and around 4k times for OLMo-1B). Finally, we train a regression model on measurements of linear representation quality in fully-trained LMs that can predict how often a term was seen in pretraining. Our model achieves low error even on inputs from a different model with a different pretraining dataset, providing a new method for estimating properties of the otherwise-unknown training data of closed-data models. We conclude that the strength of linear representations in LMs contains signal about the models' pretraining corpora that may provide new avenues for controlling and improving model behavior: particularly, manipulating the models' training data to meet specific frequency thresholds. We release our code to support future work.