Evaluating Large Language Models through Role-Guide and Self-Reflection: A Comparative Study
{kind=link}
Abstract
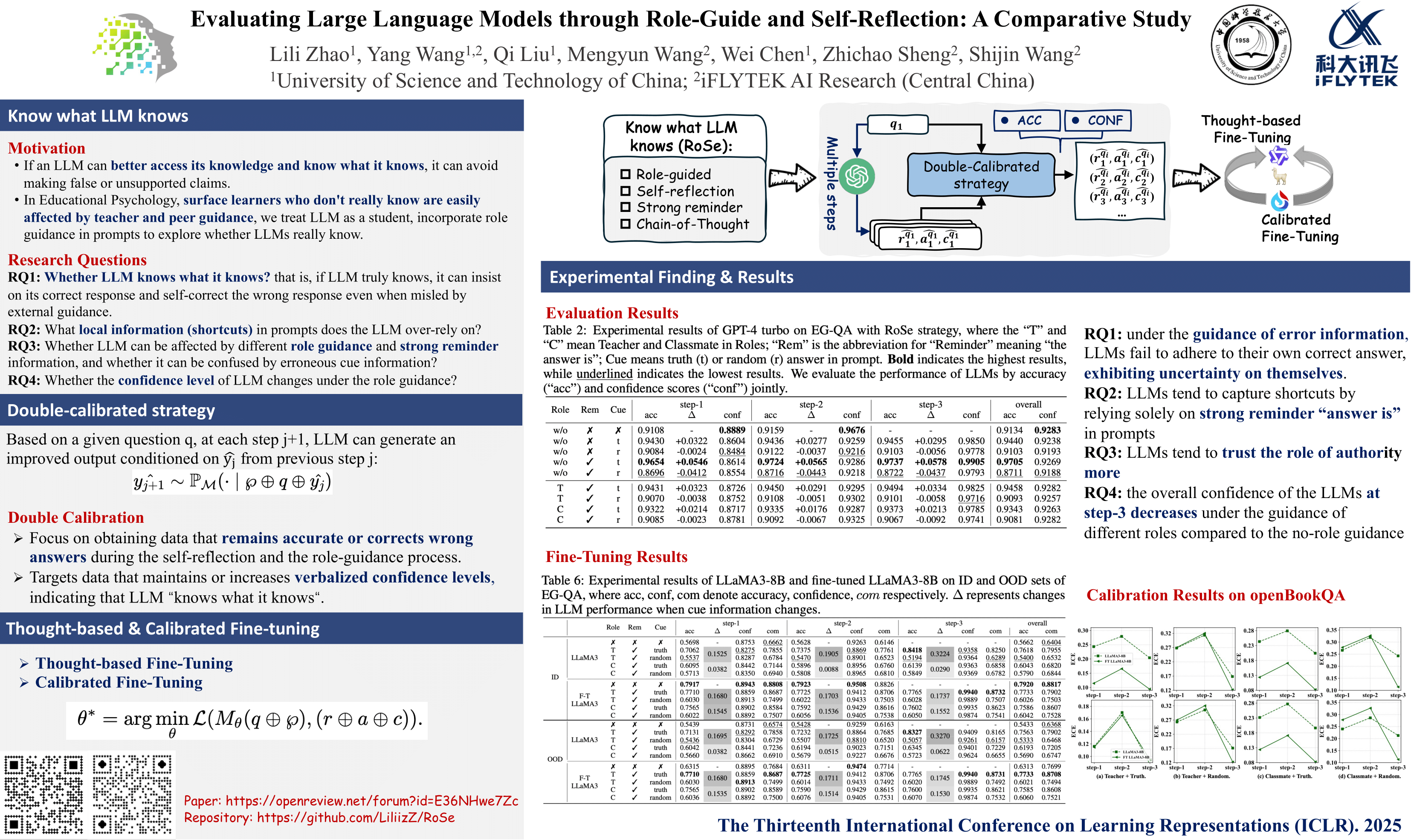
Large Language Models fine-tuned with Reinforcement Learning from Human Feedback (RLHF-LLMs) can over-rely on aligned preferences without truly gaining self-knowledge, leading to hallucination and biases. If an LLM can better access its knowledge and know what it knows, it can avoid making false or unsupported claims. Therefore, it is crucial to evaluate whether LLMs have the ability to know what they know, as it can help to ensure accuracy and faithfulness in real-world applications. Inspired by research in Educational Psychology, surface learners who don’t really know are easily affected by teacher and peer guidance, we treat LLM as a student, incorporate role guidance in prompts to explore whether LLMs really know. Specifically, we propose a novel strategy called Role-Guided and Self-Reflection (RoSe) to fully assess whether LLM “knows it knows”. We introduce multiple combinations of different roles and strong reminder in prompts combined with self-reflection to explore what local information in prompt LLMs rely on and whether LLMs remain unaffected by external guidance with varying roles. Our findings reveal that LLMs are very sensitive to the strong reminder information. Role guidance can help LLMs reduce their reliance on strong reminder. Meanwhile, LLMs tend to trust the role of authority more when guided by different roles. Following these findings, we propose a double-calibrated strategy with verbalized confidence to extract well-calibrated data from closed-source LLM and fine-tune open-source LLMs. Extensive experiments conducted on fine-tuning open-source LLMs demonstrate the effectiveness of double-calibrated strategy in mitigating the reliance of LLMs on local information. For a thorough comparison, we not only employ public JEC-QA and openBookQA datasets, but also construct EG-QA which contains English Grammar multiple-choice question-answering and 14 key knowledge points for assessing self-knowledge and logical reasoning.