Competing Large Language Models in Multi-Agent Gaming Environments
Jen-Tse Huang ⋅ Eric John Li ⋅ Man Ho LAM ⋅ Tian Liang ⋅ Wenxuan Wang ⋅ Youliang Yuan ⋅ Wenxiang Jiao ⋅ Xing Wang ⋅ Zhaopeng Tu ⋅ Michael Lyu
2025 Poster
{kind=link}
Abstract
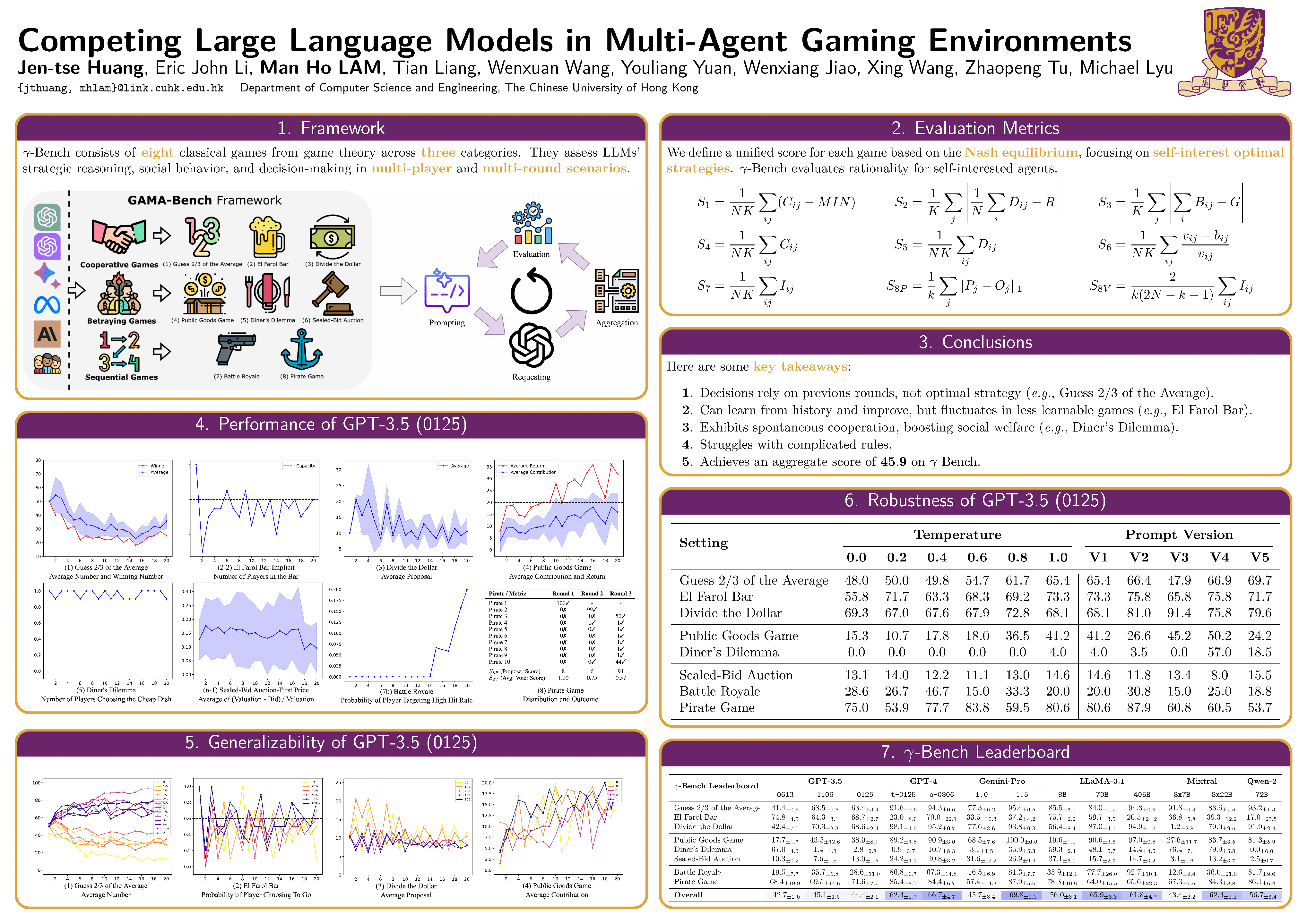
Decision-making is a complex process requiring diverse abilities, making it an excellent framework for evaluating Large Language Models (LLMs). Researchers have examined LLMs' decision-making through the lens of Game Theory. However, existing evaluation mainly focus on two-player scenarios where an LLM competes against another. Additionally, previous benchmarks suffer from test set leakage due to their static design. We introduce GAMA($\gamma$)-Bench, a new framework for evaluating LLMs' Gaming Ability in Multi-Agent environments. It includes eight classical game theory scenarios and a dynamic scoring scheme specially designed to quantitatively assess LLMs' performance. $\gamma$-Bench allows flexible game settings and adapts the scoring system to different game parameters, enabling comprehensive evaluation of robustness, generalizability, and strategies for improvement. Our results indicate that GPT-3.5 demonstrates strong robustness but limited generalizability, which can be enhanced using methods like Chain-of-Thought. We also evaluate 13 LLMs from 6 model families, including GPT-3.5, GPT-4, Gemini, LLaMA-3.1, Mixtral, and Qwen-2. Gemini-1.5-Pro outperforms others, scoring of $69.8$ out of $100$, followed by LLaMA-3.1-70B ($65.9$) and Mixtral-8x22B ($62.4$). Our code and experimental results are publicly available at https://github.com/CUHK-ARISE/GAMABench.
Video
Chat is not available.
Successful Page Load