Visual Haystacks: A Vision-Centric Needle-In-A-Haystack Benchmark
{kind=link}
Abstract
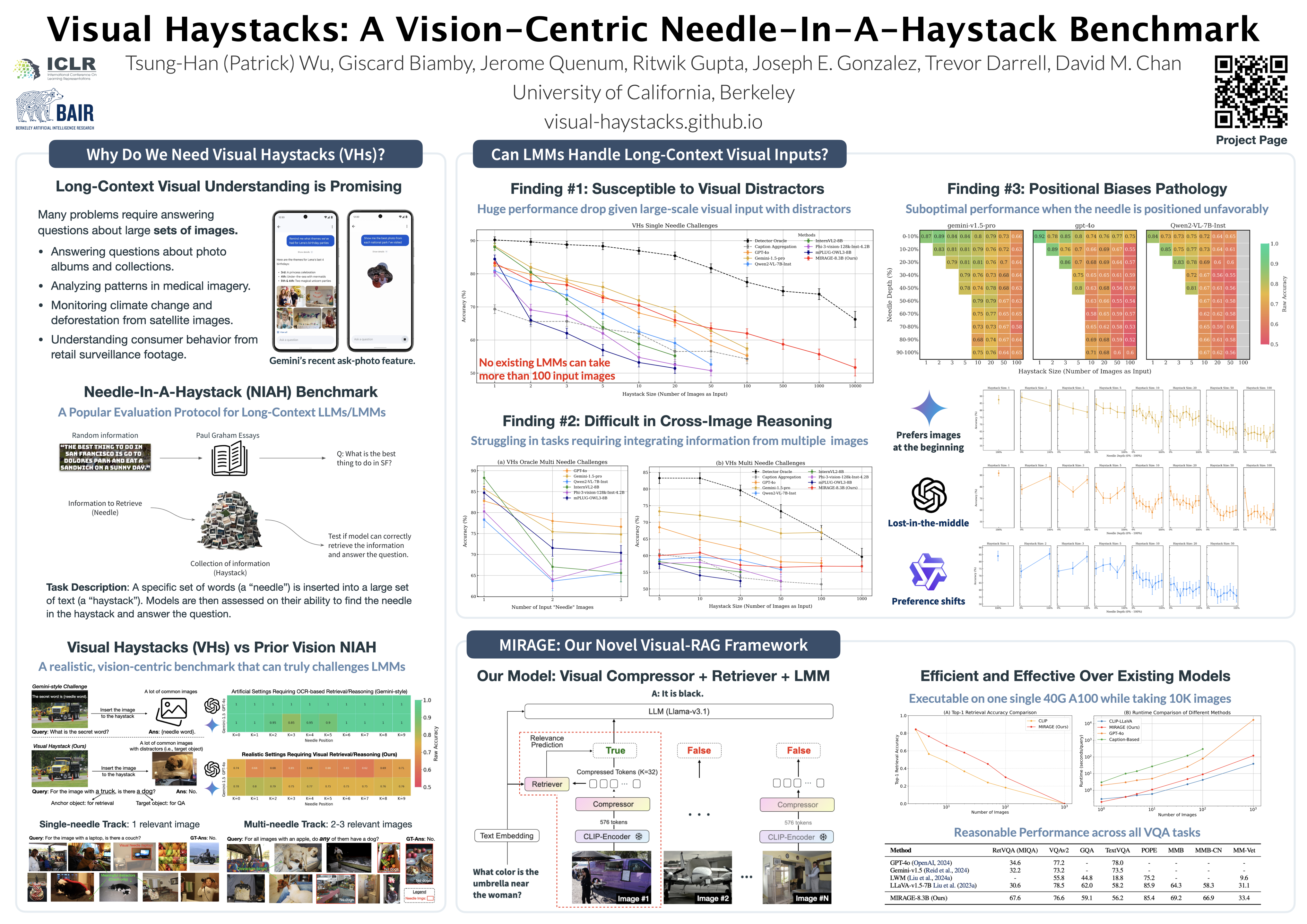
Large Multimodal Models (LMMs) have made significant strides in visual question-answering for single images. Recent advancements like long-context LMMs have allowed them to ingest larger, or even multiple, images. However, the ability to process a large number of visual tokens does not guarantee effective retrieval and reasoning for multi-image question answering (MIQA), especially in real-world applications like photo album searches or satellite imagery analysis. In this work, we first assess the limitations of current benchmarks for long-context LMMs. We address these limitations by introducing a new vision-centric, long-context benchmark, "Visual Haystacks (VHs)". We comprehensively evaluate both open-source and proprietary models on VHs, and demonstrate that these models struggle when reasoning across potentially unrelated images, perform poorly on cross-image reasoning, as well as exhibit biases based on the placement of key information within the context window. Towards a solution, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), an open-source, lightweight visual-RAG framework that processes up to 10k images on a single 40G A100 GPU—far surpassing the 1k-image limit of contemporary models. MIRAGE demonstrates up to 13% performance improvement over existing open-source LMMs on VHs, sets a new state-of-the-art on the RetVQA multi-image QA benchmark, and achieves competitive performance on single-image QA with state-of-the-art LMMs. Our dataset, model, and code are available at: https://visual-haystacks.github.io.