Semi-Supervised CLIP Adaptation by Enforcing Semantic and Trapezoidal Consistency
{kind=link}
Abstract
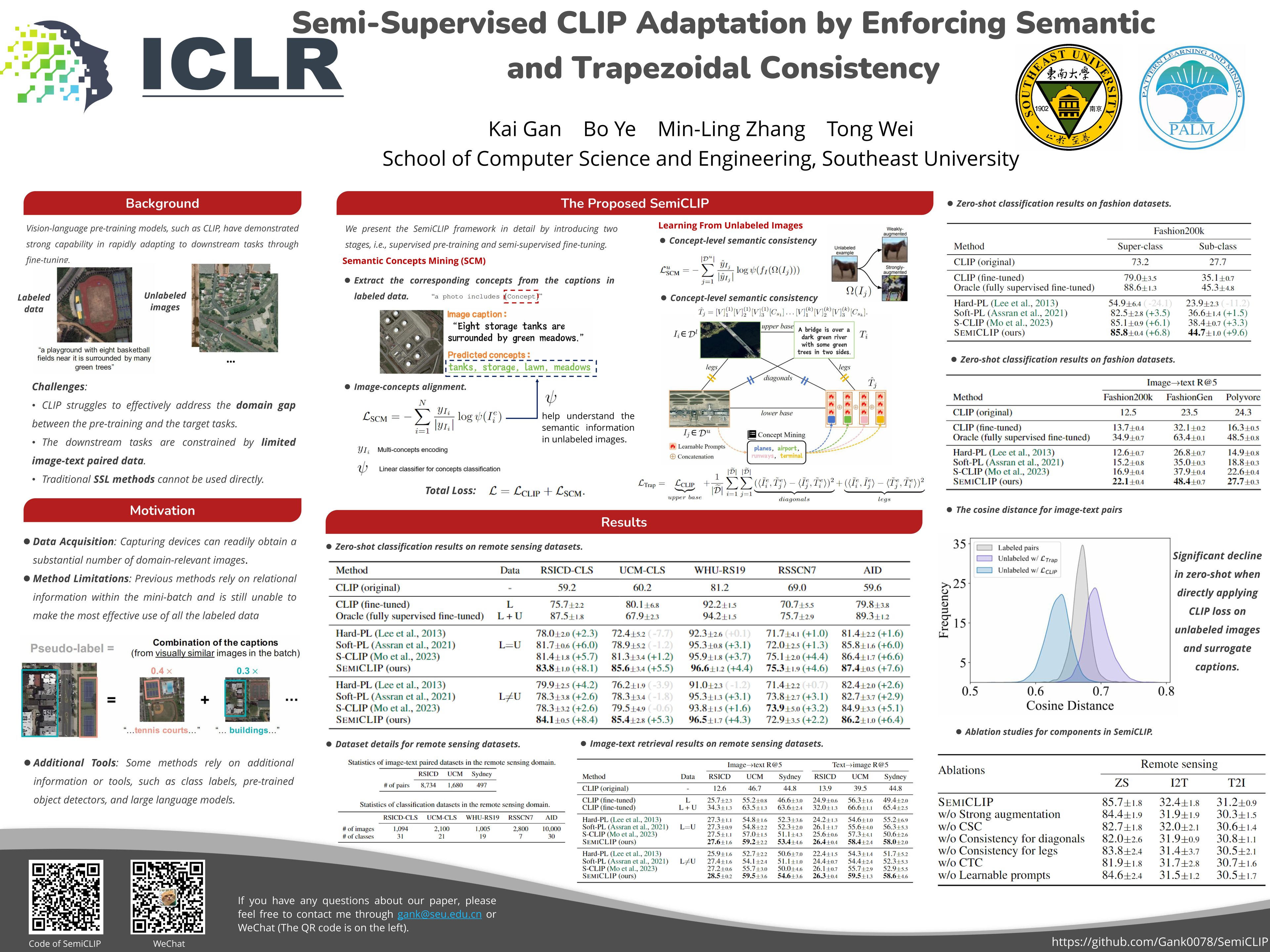
Vision-language pre-training models, such as CLIP, have demonstrated strong capability in rapidly adapting to downstream tasks through fine-tuning, and have been widely applied across various tasks. However, when the downstream tasks are constrained by limited image-text paired data, CLIP struggles to effectively address the domain gap between the pre-training and the target tasks. To address this limitation, we propose a novel semi-supervised CLIP training method coined SemiCLIP that leverages a small amount of image-text pairs alongside a large volume of images without text descriptions to enhance CLIP’s cross-modal alignment. To effectively utilize unlabeled images, we introduce semantic concept mining to improve task-specific visual representations by matching images with relevant concepts mined from labeled data. Leveraging matched semantic concepts, we construct learnable surrogate captions for unlabeled images and optimize a trapezoidal consistency to regulate the geometric structure of image-text pairs in the representation space. Experimental results demonstrate that our approach significantly improves the adaptability of CLIP in target tasks with limited labeled data, achieving gains ranging from 1.72\% -- 6.58\% for zero-shot classification accuracy and 2.32\% -- 3.23\% for image-text retrieval performance on standard benchmarks. The source code is available at https://github.com/Gank0078/SemiCLIP.