Tailoring Mixup to Data for Calibration
{kind=link}
Abstract
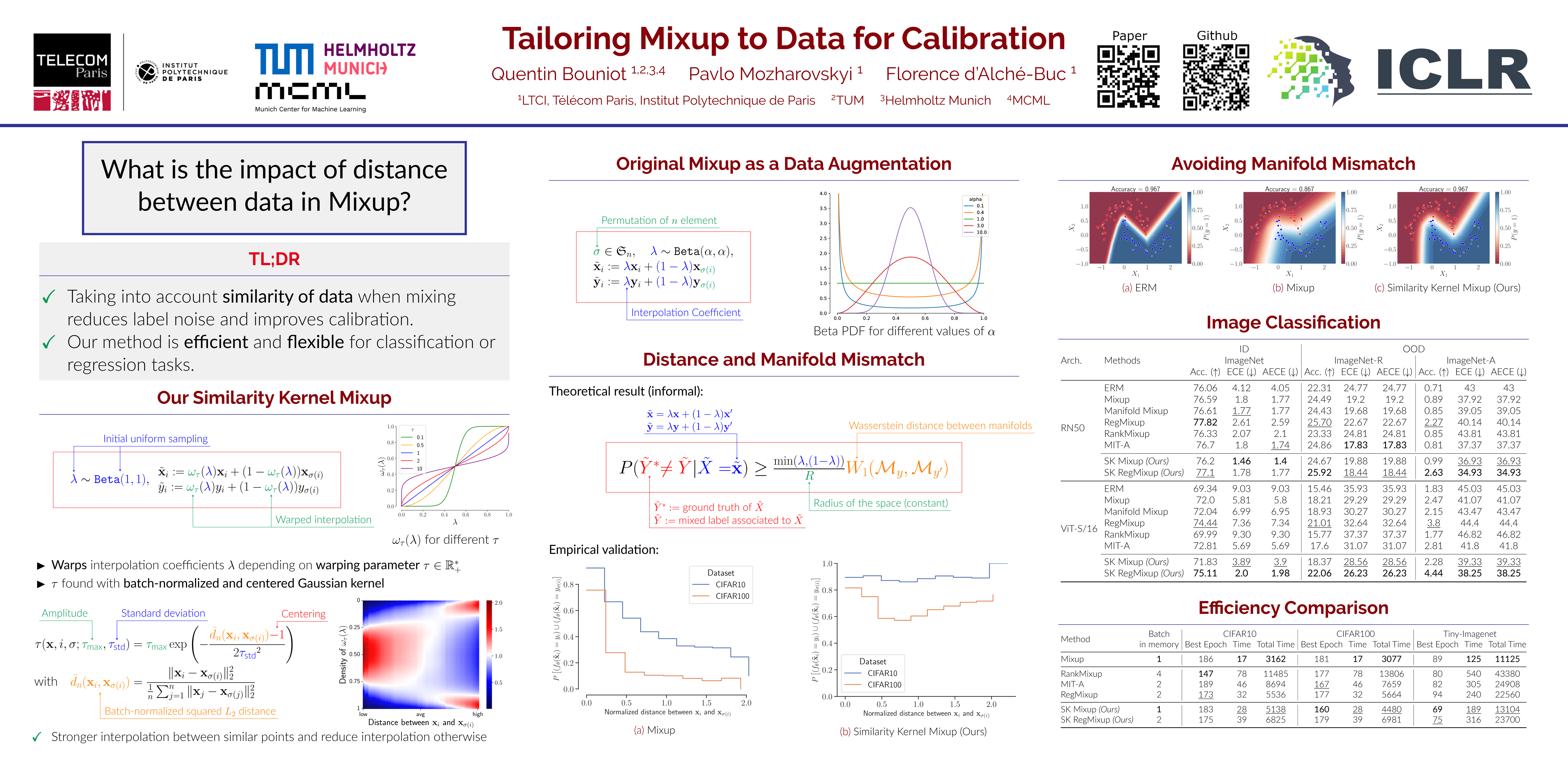
Among all data augmentation techniques proposed so far, linear interpolation of training samples, also called Mixup, has found to be effective for a large panel of applications. Along with improved predictive performance, Mixup is also a good technique for improving calibration. However, mixing data carelessly can lead to manifold mismatch, i.e., synthetic data lying outside original class manifolds, which can deteriorate calibration. In this work, we show that the likelihood of assigning a wrong label with mixup increases with the distance between data to mix. To this end, we propose to dynamically change the underlying distributions of interpolation coefficients depending on the similarity between samples to mix, and define a flexible framework to do so without losing in diversity. We provide extensive experiments for classification and regression tasks, showing that our proposed method improves predictive performance and calibration of models, while being much more efficient.