Boost Self-Supervised Dataset Distillation via Parameterization, Predefined Augmentation, and Approximation
{kind=link}
Abstract
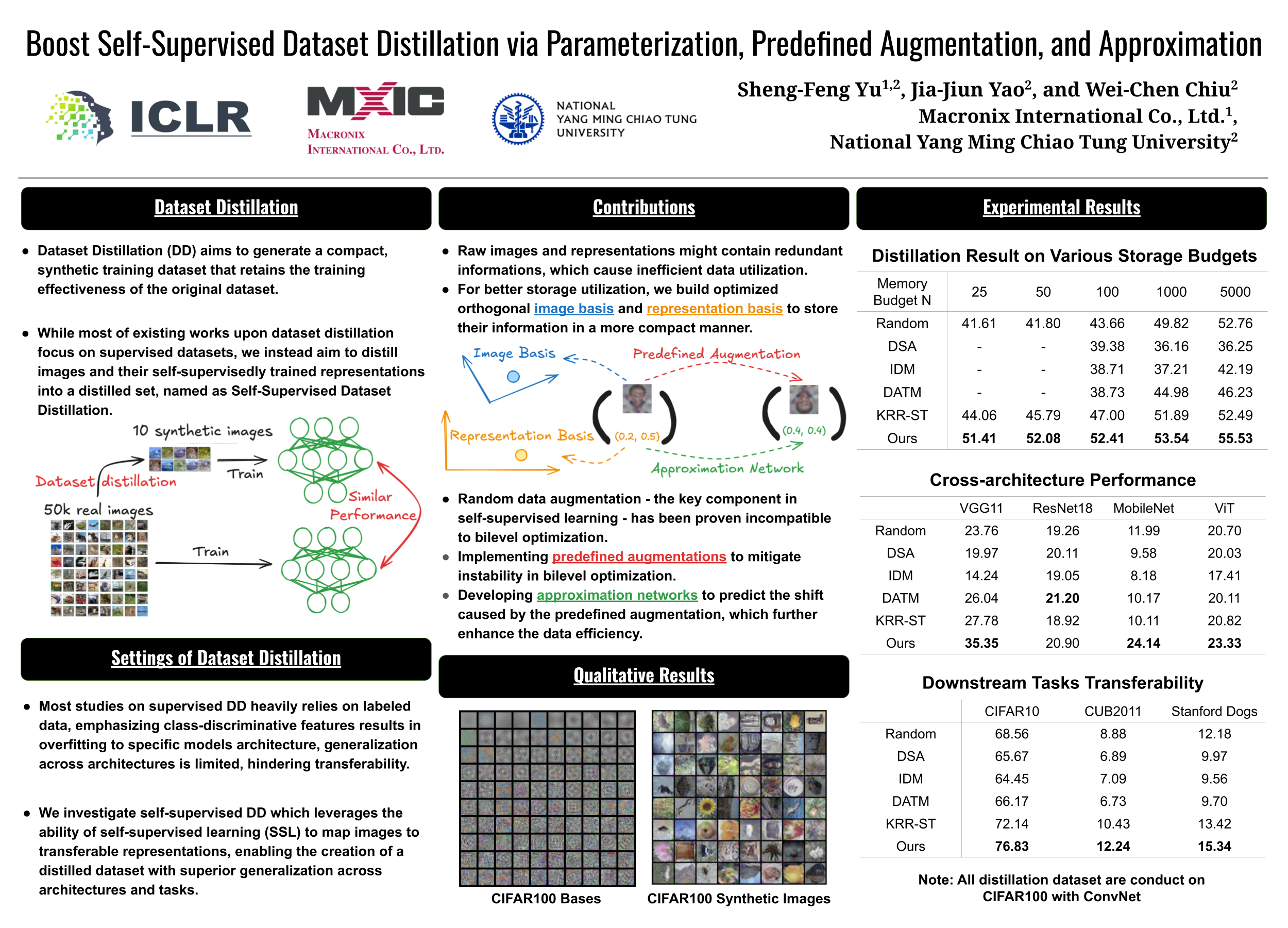
Although larger datasets are crucial for training large deep models, the rapid growth of dataset size has brought a significant challenge in terms of considerable training costs, which even results in prohibitive computational expenses. Dataset Distillation becomes a popular technique recently to reduce the dataset size via learning a highly compact set of representative exemplars, where the model trained with these exemplars ideally should have comparable performance with respect to the one trained with the full dataset. While most of existing works upon dataset distillation focus on supervised datasets, \todo{we instead aim to distill images and their self-supervisedly trained representations into a distilled set. This procedure, named as Self-Supervised Dataset Distillation, effectively extracts rich information from real datasets, yielding the distilled sets with enhanced cross-architecture generalizability.} Particularly, in order to preserve the key characteristics of original dataset more faithfully and compactly, several novel techniques are proposed: 1) we introduce an innovative parameterization upon images and representations via distinct low-dimensional bases, where the base selection for parameterization is experimentally shown to play a crucial role; 2) we tackle the instability induced by the randomness of data augmentation -- a key component in self-supervised learning but being underestimated in the prior work of self-supervised dataset distillation -- by utilizing predetermined augmentations; 3) we further leverage a lightweight network to model the connections among the representations of augmented views from the same image, leading to more compact pairs of distillation. Extensive experiments conducted on various datasets validate the superiority of our approach in terms of distillation efficiency, cross-architecture generalization, and transfer learning performance.