Mechanistic Interpretability Meets Vision Language Models: Insights and Limitations
{kind=link}
Abstract
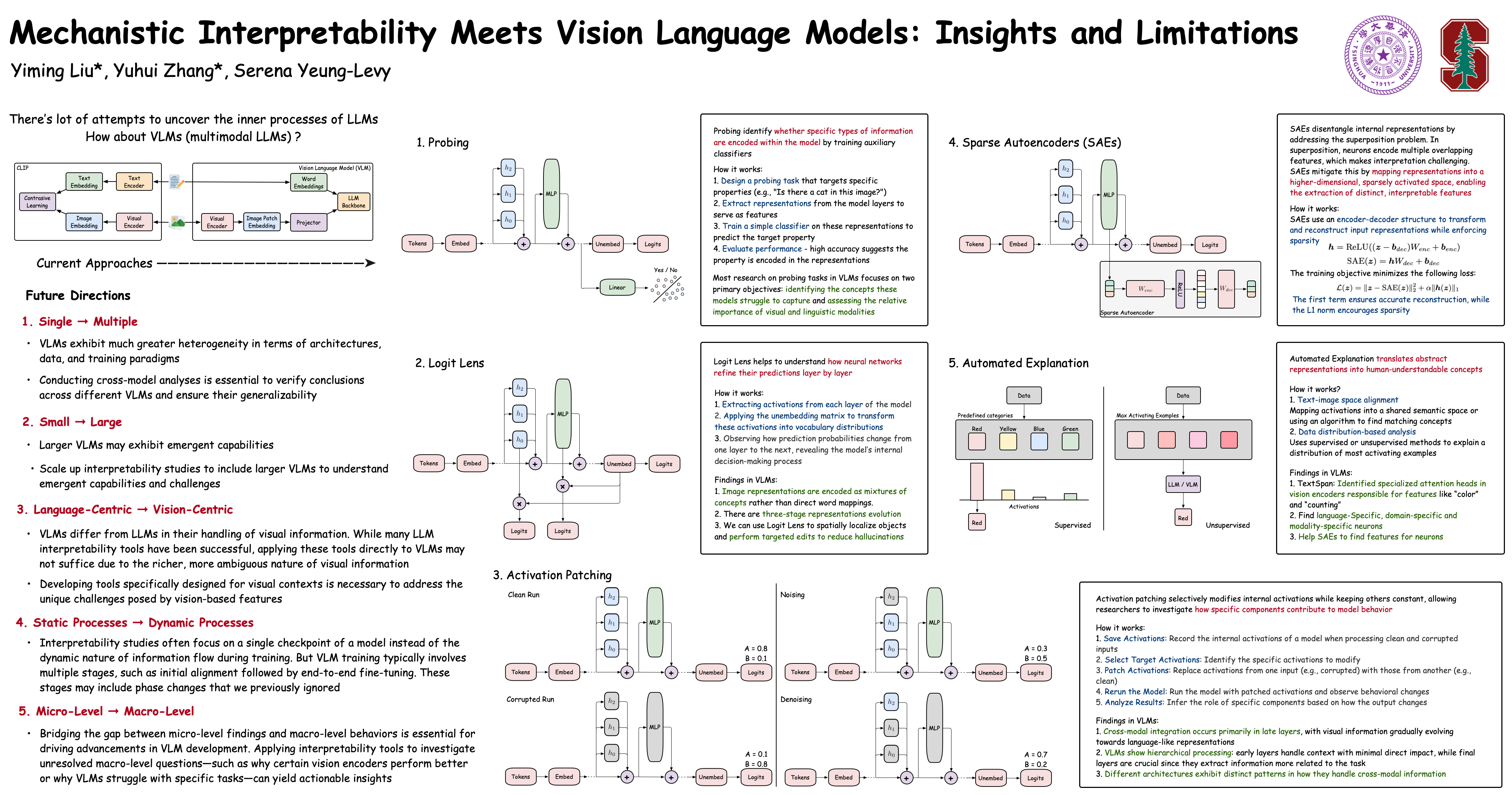
Vision language models (VLMs), such as GPT-4o, have rapidly evolved, demonstrating impressive capabilities across diverse tasks. However, much of the progress in this field has been driven by engineering efforts, with a limited understanding of how these models work. The lack of scientific insight poses challenges to further enhancing their robustness, generalization, and interpretability, especially in high-stakes settings. In this work, we systematically review the use of mechanistic interpretability methods to foster a more scientific and transparent understanding of VLMs. Specifically, we examine five prominent techniques: probing, activation patching, logit lens, sparse autoencoders, and automated explanation. We summarize the key insights these methods provide into how VLMs process information and make decisions. We also discuss critical challenges and limitations that must be addressed to further advance the field.