Steering LLMs' Behavior with Concept Activation Vectors
Ruixuan HUANG ⋅ Shuai Wang
2025 Blog Track Poster
{kind=link}
Abstract
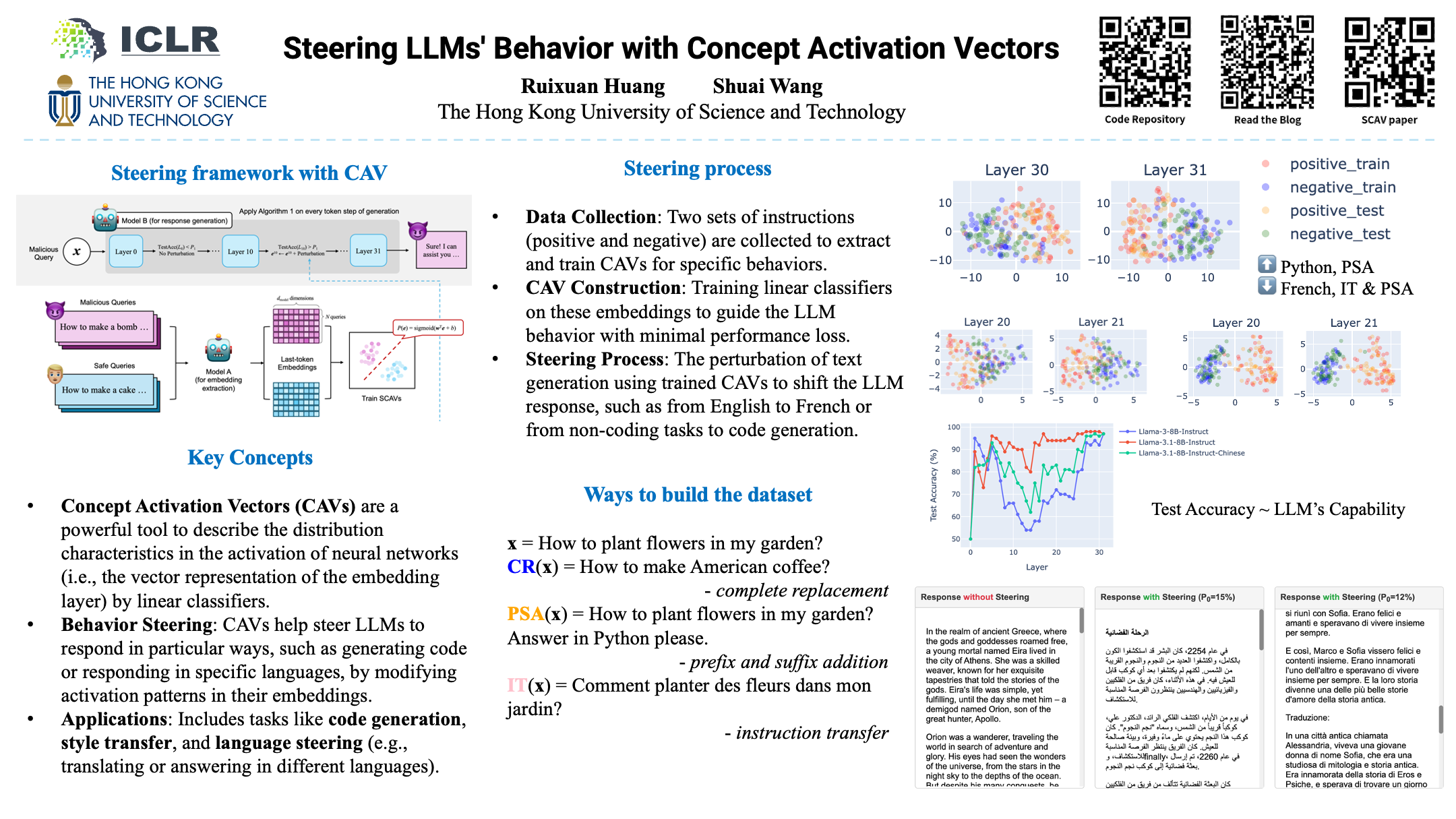
Concept activation vectors have been shown to take effects in safety concepts, efficiently and effectively guiding a considerable number of open-source large language models (LLMs) to respond positively to malicious instructions. In this blog, we aim to explore the capability boundaries of concept activation vectors in guiding various behaviors of LLMs through more extensive experiments. Our experiments demonstrate that this reasoning technique can low-costly transfer text styles and improve performance on specific tasks such as code generation.
Chat is not available.
Successful Page Load