NeRV-Diffusion: Diffuse Implicit Neural Representation for Video Synthesis
{kind=link}
Abstract
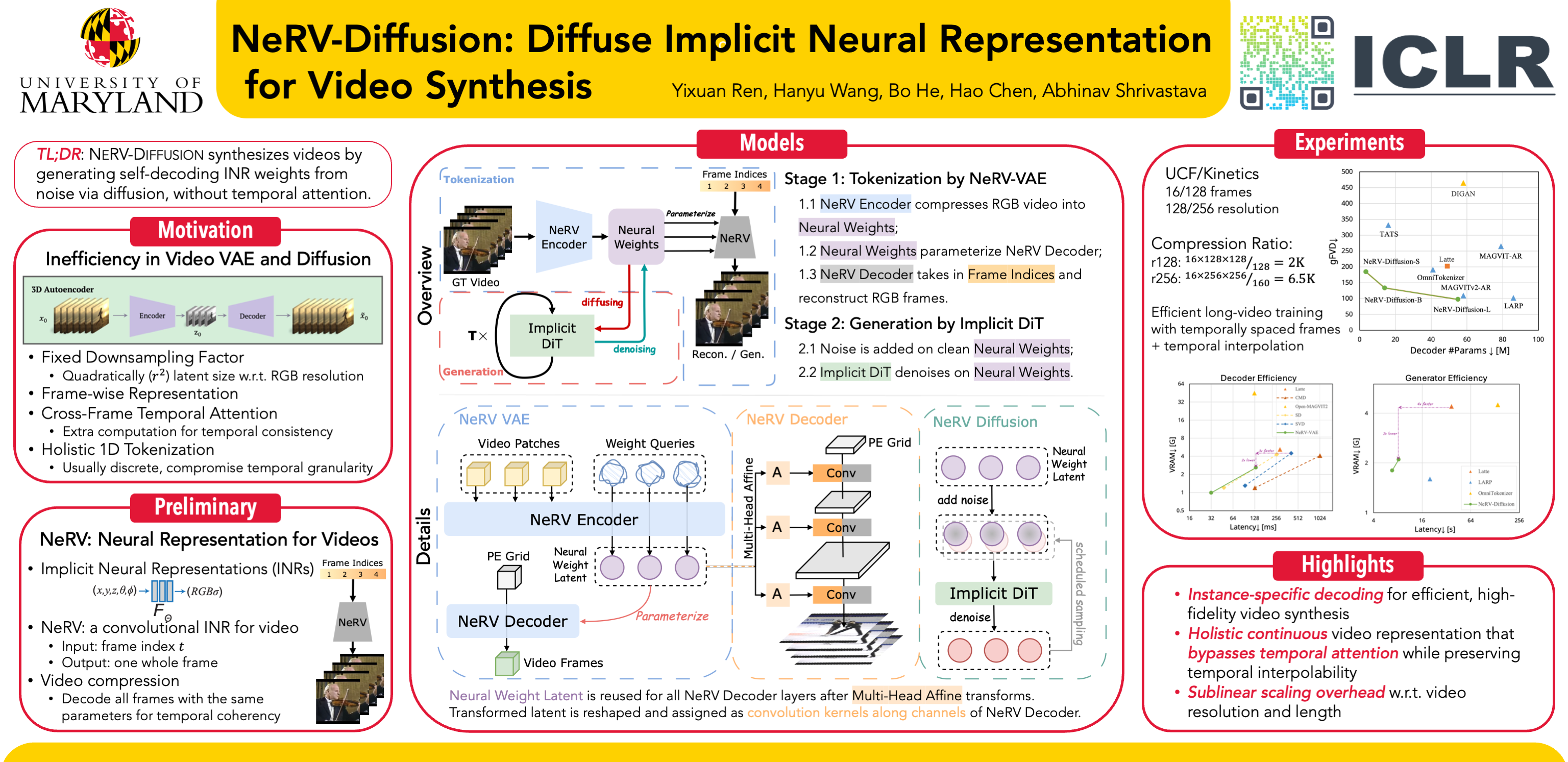
We present NeRV-Diffusion, an implicit latent video diffusion model that synthesizes videos via generating neural network weights. The generated weights can be arranged as the parameters of a convolutional network, forming an implicit neural representation (INR) and decoding into videos with frame indices as the input. Our framework consists of two stages: First, a hypernetwork-based tokenizer that encodes raw videos from pixel space to neural parameter space, and the bottleneck latent serves as INR weights to decode; Second, an implicit diffusion transformer that denoises on the latent INR weights. In contrast to traditional video tokenizers that compress videos into frame-wise feature maps, NeRV-Diffusion generates a video as a compact dedicated neural network. This continuous holistic video representation obviates temporal cross-frame attentions while preserving flexible temporal interpolability. The INR decoder and weight latent feature sublinear complexity overhead regarding video resolution and length increase with additional upsampling layers. To enable Gaussian-distributed neural weights with high expressiveness, we reuse the bottleneck latent across all INR layers, as well as reform its weight modulation, upsampling connection and input coordinates. We also introduce SNR-adaptive loss weighting and scheduled sampling for effective training of the implicit diffusion model. NeRV-Diffusion reaches superior video synthesis quality over previous INR-based models and comparable performance to most recent state-of-the-art non-implicit models on real-world video benchmarks including UCF-101 and Kinetics-600. It also achieves outstanding decoding and generation efficiency when scaling up to high-resolution and long videos.